Thank you for reading this post, don't forget to subscribe!
В нашей конфигурации мы будем использовать следующую схему:
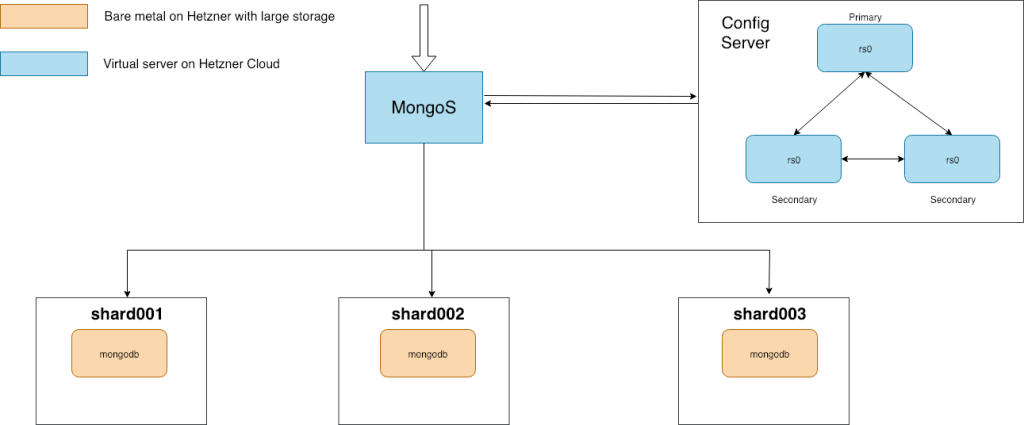
Более универсальной схемой будет считаться следующая, она предполагает отказоустойчивость:
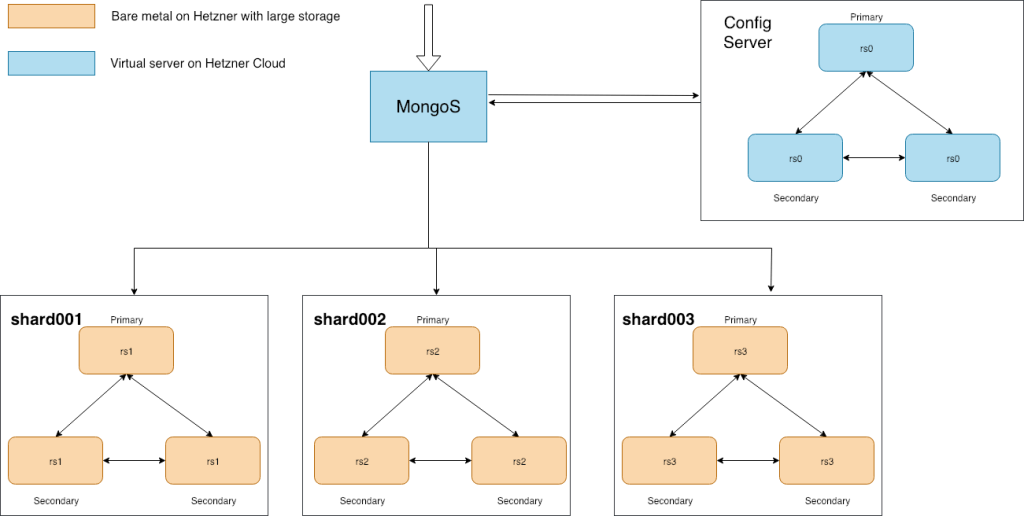
Начнем с установки mongodb демонов на сервера, будем использовать для этого официальную документацию
https://docs.mongodb.com/manual/tutorial/install-mongodb-on-red-hat/
config первого CFG реплика сет сервера для mongo
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
systemLog: destination: file logAppend: true path: /var/log/mongodb/mongod.log storage: dbPath: /var/lib/mongo journal: enabled: true processManagement: fork: true pidFilePath: /var/run/mongodb/mongod.pid timeZoneInfo: /usr/share/zoneinfo net: port: 27017 bindIp: mongos-cfg1 replication: oplogSizeMB: 10240 replSetName: "replconfig01" sharding: clusterRole: configsvr |
Для остальных двух cfg серверов все по аналогии, меняем только bindIP.
Также стоит обратить внимание, что все ноды были описаны предварительно в /etc/hosts и файл hosts разлит на все ноды.
192.168.1.2 mongos
192.168.1.3 mongos-cfg1
192.168.1.4 mongos-cfg2
192.168.1.5 mongos-cfg3
192.168.1.6 dbstore1
192.168.1.7 dbstore2
192.168.1.8 dbstore3
Подключаемся к нашему первому серверу mongos-cfg1 и делаем репликасет
mongo --host mongos-cfg1 --port 27017
выполняем:
|
1 2 3 4 5 6 7 8 9 10 11 |
rs.initiate( { _id: "replconfig01", configsvr: true, members: [ { _id : 0, host : "mongos-cfg1:27017" }, { _id : 1, host : "mongos-cfg2:27017" }, { _id : 2, host : "mongos-cfg3:27017" } ] } ) |
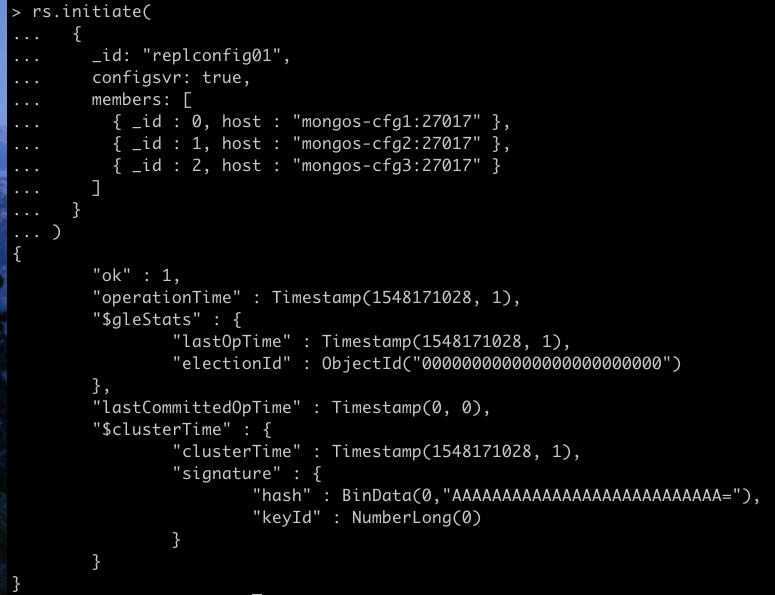
В выводе «ок»: 1 — означает успешное выполнение нашей предыдущей команды.
Проверяем состояние всех трех серверов, должен быть 1 Primary и 2 Secondary, команды для проверки состояния:
rs.isMaster()
rs.status()
Сконфигурируем наши сторейджи для монги, конфиг такой
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
systemLog: destination: file logAppend: true path: /var/log/mongodb/mongod.log storage: dbPath: /opt/mongo directoryPerDB: true journal: enabled: true processManagement: fork: true pidFilePath: /var/run/mongodb/mongod.pid timeZoneInfo: /usr/share/zoneinfo net: port: 27017 bindIp: dbstore1 sharding: clusterRole: shardsvr |
Для каталога хранения данных mongo указанной dbPath проверим/установим верного владельца:
chown -R mongod:mongod /opt/mongo/
Запускаем сервисы, проверяем, что порт 27017 слушают нужные нам демоны.
Последние и самое интересное, настройка mongos — роутера всех запросов в наш будущий кластер.
После того, как на будущий роутер установлен пакет mongod, создадим service файл для того, чтобы mongos запускался автоматически
!!! Непосредственно mongod сервис должен быть остановлен и исключен из автозапуска !!!
nano /etc/systemd/system/mongos.service
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
[Unit] Description=High-performance, schema-free document-oriented database After=network.target Documentation=https://docs.mongodb.org/manual [Service] Type=forking User=root Group=root ExecStart=/usr/bin/mongos -f /etc/mongos.conf PIDFile=/var/run/mongos.pid LimitFSIZE=infinity LimitCPU=infinity LimitAS=infinity LimitNOFILE=64000 LimitNPROC=64000 LimitMEMLOCK=infinity TasksMax=infinity TasksAccounting=false [Install] WantedBy=multi-user.target |
Выполним команду для обновление списка сервисов
systemctl daemon-reload
systemctl enable mongos
Наш конфигурационный файл для mongos /etc/mongos.conf будет следующим:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
systemLog: destination: file logAppend: true path: /var/log/mongodb/mongos.log processManagement: fork: true pidFilePath: /var/run/mongos.pid timeZoneInfo: /usr/share/zoneinfo net: port: 27017 bindIp: 0.0.0.0 maxIncomingConnections: 20000 sharding: configDB: "replconfig01/mongos-cfg1:27017,mongos-cfg2:27017,mongos-cfg3:27017" |
Запускаем mongos сервис
systemctl start mongos
Проверяем, что работает
# netstat -ntupl | grep mongos
tcp 0 0 0.0.0.0:27017 0.0.0.0:* LISTEN 3570/mongos
Также в логе /var/log/mongodb/mongos.log должны быть строки с успешным подключением к нашему config replicaset mongo
Successfully connected to mongos-cfg1:27017
Successfully connected to mongos-cfg2:27017
Successfully connected to mongos-cfg3:27017
Последний штрих, регистрация наших mongo shard серверов в mongos роутере
На сервере mongos, подключаемся к нашему кластеру:
mongo --host mongos --port 27017
и добавляем наши shard сервера
sh.addShard( "dbstore1:27017")
sh.addShard( "dbstore2:27017")
sh.addShard( "dbstore3:27017")
Перейдем к практике. Сгенерируем данные и сделаем им шардированние.
Сгенерировать данные можно следующем способом
Создаем базу данных в mongo (на сервере mongos) и заходим в нее, далее выполним несколько команд чтобы сгенерировать 1 000 000 документов.
|
1 2 3 4 |
var day = 1000 * 60 * 60 * 24; var randomDate = function () {return new Date(Date.now() - (Math.floor(Math.random() * day)));} var randomName = function() {return (Math.random()+1).toString(36).substring(2);} for (var i = 1; i <= 1000000; ++i) {db.lemp.insert({name: randomName(), creationDate: randomDate(), uid: i});} |
После того как данные сгенерированны, надо сделать индекс шардирорвания.
Например, коллекция lemp уже содержит сгенерированные данные по примеру чуть выше.
|
1
2
3
4
|
mongos> show dbs
admin 0.000GB
config 0.002GB
lemp 0.433GB
|
|
1
|
mongos> use lemp
|
Для начала включаем шардирование для определенной коллекции
|
1
|
mongos> sh.enableSharding("lemp")
|
Проверем, что шардинг включился, команда sh.status() должна отоброзить в переменных статуса коллекции «partitioned» : true
|
1
2
3
|
...
{ "_id" : "lemp", "primary" : "shard0001", "partitioned" : true, "version" : { "uuid" : UUID("e0cb2b29-8028-455a-979c-386821998b16"), "lastMod" : 1 } }
...
|
Визуальное представление наших документов в коллекции
mongos> show collections
lemp
stack
В lemp для lemp будем строить хешированный индекс по полю id, не сильно удачно были сгенерированы данные для примера, но постараемся не запутаться.
Создаем индекс
mongos> db.lemp.createIndex({_id:"hashed"},{background:true})
Выполняем шардирование
mongos> sh.shardCollection("lemp.lemp",{"_id":"hashed"})
После данной команды должен запуститься балансировщик и чанки (chunks — части данных распределяющиеся между шардами) будут перемещаться по шардам
На скрине ниже, видно наличие 11 чанков распределенных по 3 шардам, 5 6 и 5 соответственно шардам 0000, 0001 и 0002
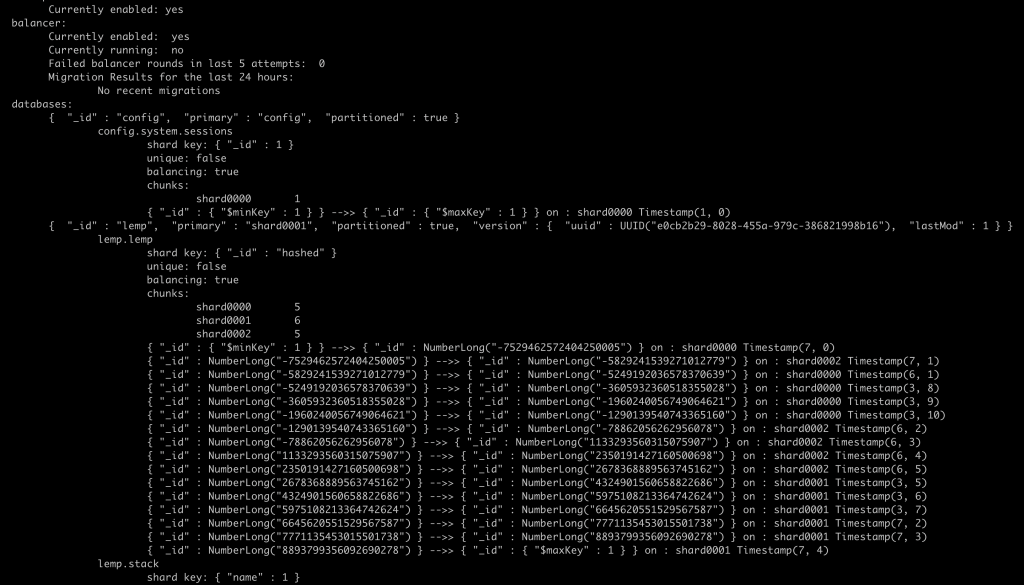
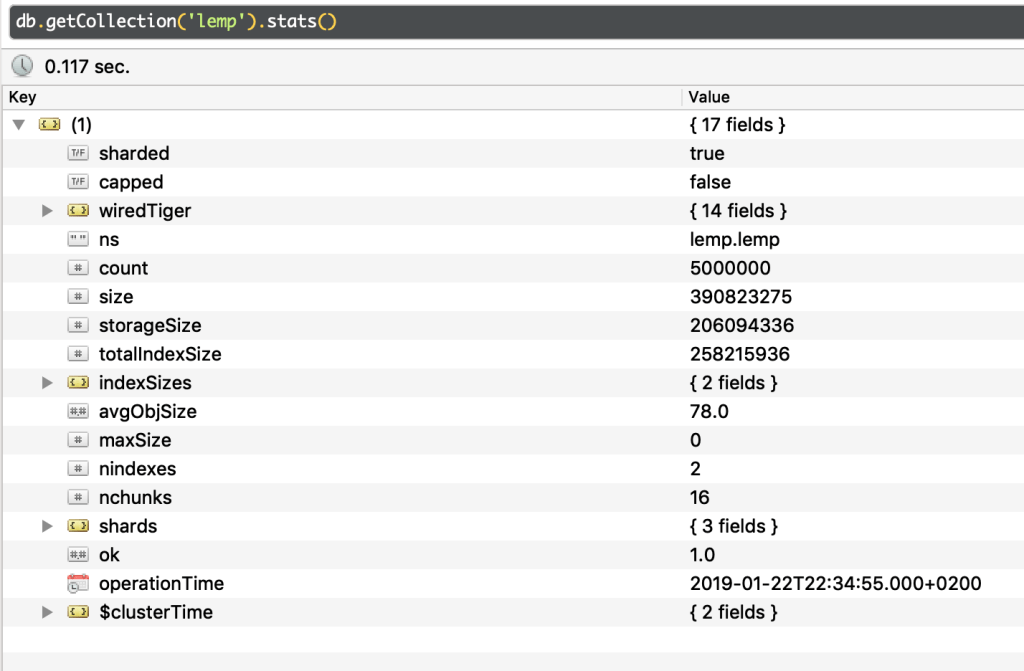
В данном примере в lemp содержится 5 000 000 документов распределенных между 3 шардами
Также в качестве замечания не стоит забывать про тюнинг самой ОС на которой будет находиться кластер.
Для mongo рекомендуется выбирать XFS
Настройки sysctl следующие
net.core.somaxconn = 4096
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_time = 120
net.ipv4.tcp_max_syn_backlog = 4096
vm.swappiness = 1
Не забываем синхронизировать время — устанавливаем ntp
А также изменить /sys/kernel/mm/transparent_hugepage/enabled с always на never
transparent_hugepage=never
в centos7 сделал делаем через tuned
Устанавливаем tuned
yum install tuned
nano /etc/tuned/no-thp/tuned.conf
|
1 2 3 4 5 |
[main] include=virtual-guest [vm] transparent_hugepages=never |
И активируем данные профайл
~# tuned-adm profile no-thp