Thank you for reading this post, don't forget to subscribe!
Hadoop – это свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов. Эта основополагающая технология хранения и обработки больших данных (Big Data) является проектом верхнего уровня фонда Apache Software Foundation.
Из чего состоит Hadoop: концептуальная архитектура
Изначально проект разработан на Java в рамках вычислительной парадигмы MapReduce, когда приложение разделяется на большое количество одинаковых элементарных заданий, которые выполняются на распределенных компьютерах (узлах) кластера и сводятся в единый результат [1].
Проект состоит из основных 4-х модулей:
- Hadoop Common – набор инфраструктурных программных библиотек и утилит, которые используются в других решениях и родственных проектах, в частности, для управления распределенными файлами и создания необходимой инфраструктуры [1];
- HDFS – распределённая файловая система, Hadoop Distributed File System – технология хранения файлов на различных серверах данных (узлах, DataNodes), адреса которых находятся на специальном сервере имен (мастере, NameNode) [2]. За счет дублирования (репликации) информационных блоков, HDFS обеспечивает надежное хранение файлов больших размеров, поблочно распределённых между узлами вычислительного кластера [1];
- YARN – система планирования заданий и управления кластером (Yet Another Resource Negotiator), которую также называют MapReduce 2.0 (MRv2) – набор системных программ (демонов), обеспечивающих совместное использование, масштабирование и надежность работы распределенных приложений [3]. Фактически, YARN является интерфейсом между аппаратными ресурсами кластера и приложениями, использующих его мощности для вычислений и обработки данных [1];
- Hadoop MapReduce – платформа программирования и выполнения распределённых MapReduce-вычислений, с использованием большого количества компьютеров (узлов, nodes), образующих кластер.
Где и зачем используется Hadoop
Выделяют несколько областей применения технологии [4]:
- поисковые и контекстные механизмы высоконагруженных веб-сайтов и интернет-магазинов (Yahoo!, Facebook, Google, AliExpress, Ebay и т.д.), в т.ч. для аналитики поисковых запросов и пользовательских логов;
- хранение, сортировка огромных объемов данных и разбор содержимого чрезвычайно больших файлов;
- быстрая обработка графических данных, например, газета New York Times с помощью хадуп и Web-сервиса Amazon Elastic Compute Cloud (EC2) всего за 36 часов преобразовала 4 терабайта изображений (TIFF-картинки размером в 405 КБ, SGML-статьи размером в 3.3 МБ и XML-файлы размером в 405 КБ) в PNG-формат размером по 800 КБ
В данной статье мы разберем как поднять Hadoop кластер c HDFS в режиме HA.
Будем использовать:
- CentOS 7
- 2 сервера будут NameNode’ами в режиме Active и Standby
- 3 сервера для DataNode с фактором репликации = 3
Основная идея HDFS использовать его без точек монтирования на конечных клиентах.
Режим High Availability появился в Hadoop с версии 2.x для решения проблемы с единой точкой входа в отличие от версии Hadoop 1.х. Это было узкое место. Сейчас реализована концепция Master/Slave для NameNode, которые в свою очередь следят за DataNode.
Архитектура HDFS HA

Отказоустойчивость.
Apache Zookeeper — служба, обеспечивающая регистрацию всех событий и отвечающая за реализацию функционала отказоустойчивости в кластере.
ZookeerFailoverController (ZKFC) является клиентом Zookeeper, который контролирует и управляет статусом NameNode. Каждая из NameNode содержит ZKFC. ZKFC отвечает за мониторинг состояния NameNodes — активный (Active) и пассивный режимы (Standby/Passive).
Службы на активной NameNode:
- Zookeeper
- Zookeeper Fail Over controller
- JournalNode
- NameNode
Службы на пассивной NameNode:
- Zookeeper
- Zookeeper Fail Over controller
- JournalNode
- NameNode
Службы на DataNode:
- Zookeeper
- JournalNode
- DataNode
| Сервер | IP | Hostname |
| Active NameNode | 192.168.0.99 | nn1.cluster.com или nn1 |
| Standby NameNode | 192.168.0.100 | nn2.cluster.com или nn2 |
| DataNode 1 | 192.168.0.101 | dn1.cluster.com или dn1 |
| DataNode 2 | 192.168.0.102 | dn2.cluster.com или dn2 |
| DataNode 3 | 192.168.0.103 | dn3.cluster.com или dn3 |
Обновляем систему, устанавливаем Java на все ноды:
yum update -y
yum install -y nano wget mc java-1.7.0-openjdk java-1.7.0-openjdk-devel
Отключаем IPv6
nano /etc/sysctl.conf
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
sysctl -p
Приводим /etc/hosts к единому виду на всех нодах
192.168.0.99 nn1.cluster.com nn1
192.168.0.100 nn2.cluster.com nn2
192.168.0.101 dn1.cluster.com dn1
192.168.0.102 dn2.cluster.com dn2
192.168.0.103 dn3.cluster.com dn3
На каждой ноде генерируем ключи и копируем на каждую ноду
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh-copy-id -i ~/.ssh/id_rsa.pub root@nn2.cluster.com
Перезагружаем sshd сервис
service sshd restart
Создаем структуру каталогов:
mkdir /home/data
mkdir /home/data/zookeeper
mkdir /home/data/nn1
chown -R 777 /home/data
Качаем стабильную версию, распаковываем и создаем симлинк для более простого поиска домашнего каталога Hadoop
cd /opt/
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.9.1/hadoop-2.9.1.tar.gz
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
tar -xvf hadoop-2.9.1.tar.gz
tar -xvf zookeeper-3.4.13.tar.gz
ln -s /opt/hadoop-2.9.1 /opt/hadoop
ln -s /opt/zookeeper-3.4.13 /opt/zookeeper
Редактируем .bashrc и добавляем переменные окружения для Java, Hadoop и Zookeeper.
export HADOOP_HOME=/opt/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_HOME=/usr/lib/jvm/jre-1.7.0-openjdk-1.7.0.191-2.6.15.4.el7_5.x86_64
export ZOOKEEPER_HOME=/opt/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
Также, рекомендуется добавить эти же переменные окружения в файл
/opt/hadoop/etc/hadoop/hadoop-env.sh
На NameNode1 (nn1) редактируем файл core-site.xml
nano /opt/hadoop/etc/hadoop/core-site.xml
Добавляем:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://ha-cluster</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/data</value> </property> <property> <name>fs.trash.interval</name> <value>10</value> </property> <property> <name>ipc.maximum.data.length</name> <value>134217728</value> </property> </configuration> |
Редактируем основной файл конфигурации hdfs-site.xml
nano /opt/hadoop/etc/hadoop/hdfs-site.xml
Добавляем:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/home/data/nn1</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.nameservices</name> <value>ha-cluster</value> </property> <property> <name>dfs.ha.namenodes.ha-cluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.ha-cluster.nn1</name> <value>192.168.0.99:9000</value> </property> <property> <name>dfs.namenode.rpc-address.ha-cluster.nn2</name> <value>192.168.0.100:9000</value> </property> <property> <name>dfs.namenode.http-address.ha-cluster.nn1</name> <value>nn1.cluster.com:50070</value> </property> <property> <name>dfs.namenode.http-address.ha-cluster.nn2</name> <value>nn2.cluster.com:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://nn1.cluster.com:8485;nn2.cluster.com:8485;dn1.cluster.com:8485;dn2.cluster.com:8485;dn3.cluster.com:8485/ha-cluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.ha-cluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>nn1.cluster.com:2181,nn2.cluster.com:2181,dn1.cluster.com:2181,dn2.cluster.com:2181,dn3.cluster.com:2181</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>30000</value> </property> </configuration> |
Обратим на важные параметры:
dfs.replication — фактор репликации данных, указываем 3, он не должен быть больше чем кол-во datanode.
Так выглядит информация о файле при репликации 3
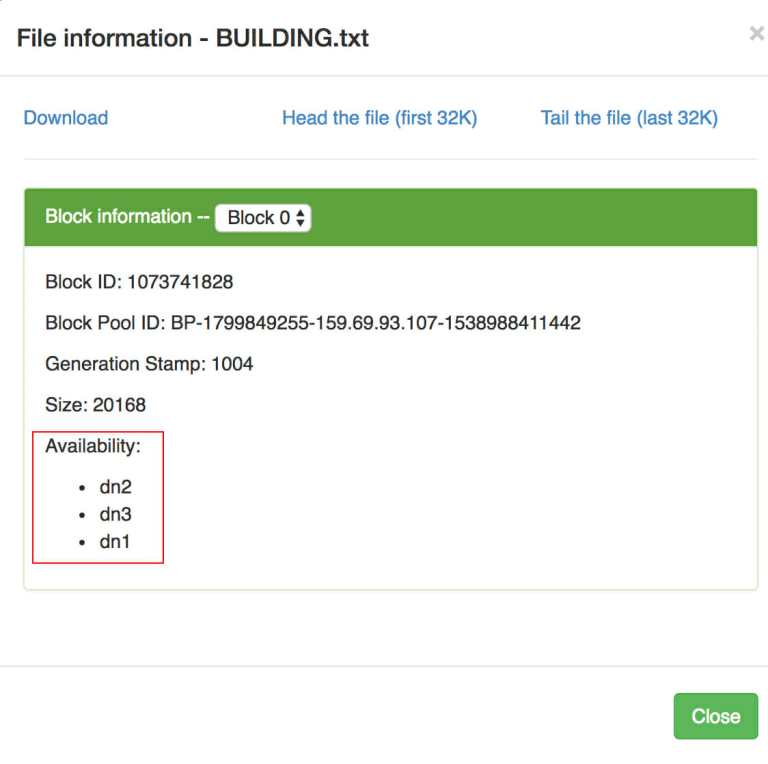
ha.zookeeper.quorum — наш zookeeper кворум, где искать ноды zk кластера, крайне необходимо для выбора лидера и всего обнаружение и регистрации состояния нод в кластере.
dfs.namenode.heartbeat.recheck-interval — интервал проверок datanode и помечать их как недоступные.
Приступаем к настройке Zookeeper
Создадим файл конфигурации
cp /opt/zookeeper/conf/zoo_sample.cfg /opt/zookeeper/conf/zoo.cfg
В основной файл настроек Zookeeper добавим все ноды нашего zk кластера
nano /opt/zookeeper/conf/zoo.cfg
|
1 2 3 4 5 6 7 8 9 10 |
tickTime=2000 initLimit=10 syncLimit=5 clientPort=2181 dataDir=/home/data/zookeeper server.1=192.168.0.99:2888:3888 server.2=192.168.0.100:2888:3888 server.3=192.168.0.101:2888:3888 server.4=192.168.0.102:2888:3888 server.5=192.168.0.103:2888:3888 |
dataDir=/home/data/zookeeper — указываем каталог для хранения данных zookeeper
server.N — перечисляем все наши сервера, находящиеся в кворуме zookeeper
Копируем наши каталоги с настроенным Hadoop (/opt/hadoop-2.9.1) и Zookeeper (/opt/zookeeper-3.4.13) на все ноды, помещаем в аналогичный каталог /opt , создаем аналогичные симлинки и прописываем .bashrc переменные окружения, также не забываем создать каталоги для хранения данных (/home/data, /home/data/zookeeper, /home/data/nn1).
Настройка DataNode серверов
Отличие состоим в том, что нам необходимо создать иопределить дополнительный каталог для хранения данных HDFS.
mkdir /home/data/datanode/
chmod 755 /home/data/datanode/
На datanode серверах редактируем файл hdfs-site.xml и добавляем в него путь к данным:
nano /opt/hadoop/etc/hadoop/hdfs-site.xml
|
1 2 3 4 |
<property> <name>dfs.datanode.data.dir</name> <value>/home/data/datanode</value> </property> |
Вернемся к настройке zookeeper, после того как мы скопировали весь каталог на все ноды, с одинаковыми конфигами, теперь нам необходимо создать уникальный файл на каждом сервере — myid. ID должен соответствовать номеру N указанному в файле zoo.cfg
пример для сервера datanode1, он имеет server N=3 в файле zoo.cfg
cat /opt/zookeeper/conf/zoo.cfg | grep 192.168.0.101
server.3=192.168.0.101:2888:3888
nano /home/data/zookeeper/myid
3
И так последовательно для каждого сервера в нашем zookeeper кворуме.
Создаем systemd скрипты для автоматического запуска сервисов после перезагрузки нод.
Список service конфигов для NameNode серверов (всего 4 шт):
nano /etc/systemd/system/journalnode.service
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[Unit] Description=Hadoop JournalNode service After=network.target After=systemd-user-sessions.service After=network-online.target [Service] User=root Type=forking ExecStart=/opt/hadoop-2.9.1/sbin/hadoop-daemon.sh start journalnode ExecStop=/opt/hadoop-2.9.1/sbin/hadoop-daemon.sh stop journalnode TimeoutSec=30 Restart=on-failure RestartSec=30 StartLimitInterval=350 StartLimitBurst=10 [Install] WantedBy=multi-user.target |
nano /etc/systemd/system/namenode.service
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[Unit] Description=Hadoop JournalNode service After=network.target After=systemd-user-sessions.service After=network-online.target [Service] User=root Type=forking ExecStart=/opt/hadoop-2.9.1/sbin/hadoop-daemon.sh start namenode ExecStop=/opt/hadoop-2.9.1/sbin/hadoop-daemon.sh stop namenode TimeoutSec=30 Restart=on-failure RestartSec=30 StartLimitInterval=350 StartLimitBurst=10 [Install] WantedBy=multi-user.target |
nano /etc/systemd/system/zkserver.service
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[Unit] Description=Hadoop JournalNode service After=network.target After=systemd-user-sessions.service After=network-online.target [Service] User=root Type=forking ExecStart=/opt/zookeeper-3.4.13/bin/zkServer.sh start ExecStop=/opt/zookeeper-3.4.13/bin/zkServer.sh stop TimeoutSec=30 Restart=on-failure RestartSec=30 StartLimitInterval=350 StartLimitBurst=10 [Install] WantedBy=multi-user.target |
nano /etc/systemd/system/zkfc.service
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[Unit] Description=Hadoop JournalNode service After=network.target After=systemd-user-sessions.service After=network-online.target [Service] User=root Type=forking ExecStart=/opt/hadoop-2.9.1/sbin/hadoop-daemon.sh start zkfc ExecStop=/opt/hadoop-2.9.1/sbin/hadoop-daemon.sh stop zkfc TimeoutSec=30 Restart=on-failure RestartSec=30 StartLimitInterval=350 StartLimitBurst=10 [Install] WantedBy=multi-user.target |
Для DataNode серверов список будет несколько иной, суммарно 3 сервиса:
Мы оставляем конфиги для:
journalnode.service
zkserver.service
Но дополнительно добавляем datanode.service
nano /etc/systemd/system/datanode.service
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[Unit] Description=Hadoop JournalNode service After=network.target After=systemd-user-sessions.service After=network-online.target [Service] User=root Type=forking ExecStart=/opt/hadoop-2.9.1/sbin/hadoop-daemon.sh start datanode ExecStop=/opt/hadoop-2.9.1/sbin/hadoop-daemon.sh stop datanode TimeoutSec=30 Restart=on-failure RestartSec=30 StartLimitInterval=350 StartLimitBurst=10 [Install] WantedBy=multi-user.target |
После добавления новых сервисов не забываем выполнить команду
systemctl daemon-reload
Приступаем к запуску нашего кластера.
Последовательность запуска крайне важна!
Условно, на нашей будующей активной namenode (сервер nn1), запускаем journalnode сервис
service journalnode start
Смотрим вывод команды jps, должена появиться journalnode демон с PID
# jps
4914 Jps
1465 JournalNode
Форматируем данную ноду nn1
nn1# hdfs namenode -format
Запускаем демон namenode
nn1# service namenode start && systemctl enable namenode
Переходим на nn2 (Standby сервер) и копируем метаданные с активной ноды (если спрашивает перезаписать существующие метаданные — отказываемся).
nn2# hdfs namenode -bootstrapStandby
Если команда выполнилась без ошибок, запускаем на nn2 демон namenode
nn2# service namenode start && systemctl enable namenode
Теперь запускаем Zookeeper на всех нодах нашего кластера, начинаем с Active Namenode (nn1), затем Standby Namenode (nn2), потом Datanode серверах (dn1, dn2, dn3):
all-servers# service zkserver start && systemctl enable zkserver
После запуска на всех нодах Zookeeper проверяем командой jps наличие сервиса QuorumPeerMain:
[root@nn1 ~]# jps
1465 JournalNode
1417 QuorumPeerMain
2104 Jps
3263 NameNode
Запускаем Datanode демона на Data node серверах:
dn# service datanode start && systemctl enable datanode
На Namenode серверах форматируем и запускаем Zookeeper fail сервис:
nn1# hdfs zkfc -formatZK
nn1# service zkfs start && systemctl enable zkfc
Вводим команду jps и смотрим наличие демона DFSZkFailoverController
[root@nn1 ~]# jps
1465 JournalNode
1417 QuorumPeerMain
2104 Jps
1467 DFSZKFailoverController
3263 NameNode
Выполняем на nn2 Standby сервере:
nn2# hdfs zkfc -formatZK
и запускаем демон
nn2# service zkfs start && systemctl enable zkfc
Проверяем jps, чтобы на nn2 запустился также DFSZkFailoverController.
Теперь проверим статус наших namenode серверов:
[root@nn1 ~]# hdfs haadmin -getServiceState nn1
active
[root@nn1 ~]# hdfs haadmin -getServiceState nn2
standby
Проверим в браузере как выглядим UI нашего кластера
<IP Namenode>:50070
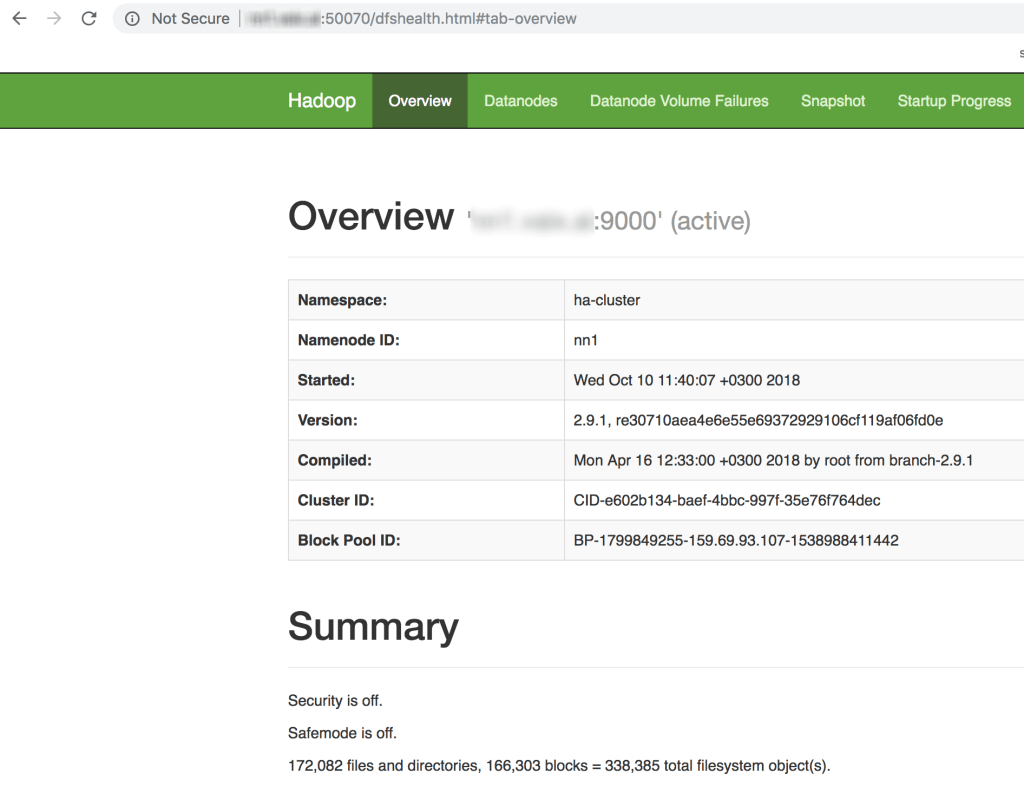
Небольшой стресс тест, чтобы проверить переключаются или нет active и standby hdfs ноды местами
На nn1 сервера находим ID процесса namenode
[root@nn1 ~]# jps
1465 JournalNode
1417 QuorumPeerMain
2104 Jps
1467 DFSZKFailoverController
3263 NameNode
и убиваем его
kill -9 3263
Дополнительно.
hdfs позволяет активировать опцию — крзина, файлы после удаления некоторое время остаються на файловой системе и затем удаляються, для этого мы добавляли в файл core-site.xml опцию fs.trash.interval, ее значение задается в минутах.
После удаления файлы будут помещаться примерно по такому пути:
hdfs fs -ls /user/hadoop/.Trash
По-умолчанию web UI доступен без пароля, включим web авторизацию на dashboard hdfs.
nn1# cd /opt/hadoop
find ./ -type f -name "web.xml"
nano ./share/hadoop/hdfs/webapps/hdfs/WEB-INF/web.xml
Добавляем
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<web-app version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee"> <security-constraint> <web-resource-collection> <web-resource-name>Protected</web-resource-name> <url-pattern>/*</url-pattern> </web-resource-collection> <auth-constraint> <role-name>admin</role-name> </auth-constraint> </security-constraint> <login-config> <auth-method>BASIC</auth-method> <realm-name>jobtrackerRealm</realm-name> </login-config> </web-app> |
Создаем в том же каталоге файл с содержимым:
nano./share/hadoop/hdfs/webapps/hdfs/WEB-INF/jetty-web.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<Configure class="org.mortbay.jetty.webapp.WebAppContext"> <Get name="securityHandler"> <Set name="userRealm"> <New class="org.mortbay.jetty.security.HashUserRealm"> <Set name="name">jobtrackerRealm</Set> <Set name="config"> <SystemProperty name="hadoop.home.dir"/>/etc/realm.properties </Set> </New> </Set> </Get> </Configure> |
Обращаем внимание на значение переменной в данной строке
<SystemProperty name="hadoop.home.dir"/>/jetty/etc/realm.properties
Тут мы указываем файл, в котором будет находиться реальное имя пользователя и пароль.
Создаем данный файл
$HADOOP_HOME/jetty/etc/realm.properties
Формат файла:
username: password,group.
У меня он находиться по данному пути и его содержимое следующее:
nn1# nano /opt/hadoop/etc/realm.properties
admin: superpassword,admin
После, перезагружаем демона namenode
nn1# service namenode stop && service namenode start
Полезные команды:
проверка статуса zk кластера
nn1# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Mode: follower
У нас должен быть на одном из серверов обязательно Mode: active, на всех остальных follower