Thank you for reading this post, don't forget to subscribe!
Мой рабочий вариант (ILM не работает) - печаль беда
Запуск EFK-стека с постоянными локальными томами Elasticsearch в Kubernetus. Так же здесь запускается ingress для Kibana, что позволит обращаться к сервису извне.
cat elasticsearch_pv.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
--- apiVersion: v1 kind: PersistentVolume metadata: name: elastic-efk-pv1 spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: local-storage local: path: /elastic-efk nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - tst-kub-worker1 --- apiVersion: v1 kind: PersistentVolume metadata: name: elastic-efk-pv2 spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: local-storage local: path: /elastic-efk nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - tst-kub-worker2 |
[/codesyntax]
cat pvc-local.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
--- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: data-es-cluster-0 spec: storageClassName: "local-storage" accessModes: - ReadWriteMany resources: requests: storage: 1Gi --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: data-es-cluster-1 spec: storageClassName: "local-storage" accessModes: - ReadWriteMany resources: requests: storage: 1Gi |
[/codesyntax]
cat elasticsearch_statefulset.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
--- apiVersion: apps/v1 kind: StatefulSet metadata: name: es-cluster namespace: kube-logging spec: serviceName: elasticsearch replicas: 2 selector: matchLabels: app: elasticsearch template: metadata: labels: app: elasticsearch spec: containers: - name: elasticsearch image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0 resources: limits: cpu: 1000m requests: cpu: 100m ports: - containerPort: 9200 name: rest protocol: TCP - containerPort: 9300 name: inter-node protocol: TCP volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data env: - name: cluster.name value: k8s-logs - name: node.name valueFrom: fieldRef: fieldPath: metadata.name - name: discovery.seed_hosts value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch" - name: cluster.initial_master_nodes value: "es-cluster-0,es-cluster-1" - name: ES_JAVA_OPTS value: "-Xms512m -Xmx512m" initContainers: - name: fix-permissions image: busybox command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"] securityContext: privileged: true volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data - name: increase-vm-max-map image: busybox command: ["sysctl", "-w", "vm.max_map_count=262144"] securityContext: privileged: true - name: increase-fd-ulimit image: busybox command: ["sh", "-c", "ulimit -n 65536"] securityContext: privileged: true volumeClaimTemplates: - metadata: name: data labels: app: elasticsearch spec: accessModes: [ "ReadWriteMany" ] storageClassName: local-storage resources: requests: storage: 1Gi |
[/codesyntax]
cat elasticsearch_svc.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
----- kind: Service apiVersion: v1 metadata: name: elasticsearch namespace: kube-logging labels: app: elasticsearch spec: selector: app: elasticsearch clusterIP: None ports: - port: 9200 name: rest - port: 9300 name: inter-node |
[/codesyntax]
cat fluentd-daemonset.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
------ apiVersion: v1 kind: ServiceAccount metadata: name: fluentd namespace: kube-logging labels: app: fluentd --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: fluentd labels: app: fluentd rules: - apiGroups: - "" resources: - pods - namespaces verbs: - get - list - watch --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd roleRef: kind: ClusterRole name: fluentd apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: fluentd namespace: kube-logging --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd namespace: kube-logging labels: app: fluentd spec: selector: matchLabels: app: fluentd template: metadata: labels: app: fluentd spec: serviceAccount: fluentd serviceAccountName: fluentd tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule containers: - name: fluentd image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1 env: - name: FLUENT_ELASTICSEARCH_HOST value: "elasticsearch.kube-logging.svc.cluster.cluster.local" - name: FLUENT_ELASTICSEARCH_PORT value: "9200" - name: FLUENT_ELASTICSEARCH_SCHEME value: "http" - name: FLUENTD_SYSTEMD_CONF value: disable resources: limits: memory: 512Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers |
[/codesyntax]
cat kibana.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
---- apiVersion: v1 kind: Service metadata: name: kibana namespace: kube-logging labels: app: kibana spec: ports: - port: 5601 selector: app: kibana --- apiVersion: apps/v1 kind: Deployment metadata: name: kibana namespace: kube-logging labels: app: kibana spec: replicas: 1 selector: matchLabels: app: kibana template: metadata: labels: app: kibana spec: containers: - name: kibana image: docker.elastic.co/kibana/kibana:7.2.0 resources: limits: cpu: 1000m requests: cpu: 100m env: - name: ELASTICSEARCH_URL value: http://elasticsearch:9200 ports: - containerPort: 5601 |
[/codesyntax]
cat kibana_ingress.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: kibana namespace: kube-logging annotations: kubernetes.io/ingress.class: nginx spec: rules: - host: kibana.cluster.local http: paths: - backend: serviceName: kibana servicePort: 5601 |
[/codesyntax]
|
1 2 3 4 5 6 7 8 9 10 11 |
Далее создаем <span class="kw2">namespace</span> для данного стека и запускаем стек<span class="sy0">:</span> kubectl create <span class="kw2">namespace</span> kube<span class="sy0">-</span>logging kubectl apply <span class="sy0">-</span>f elasticsearch_pv<span class="sy0">.</span>yaml <span class="sy0">-</span>n kube<span class="sy0">-</span>logging kubectl apply <span class="sy0">-</span>f pvc<span class="sy0">-</span>local<span class="sy0">.</span>yaml <span class="sy0">-</span>n kube<span class="sy0">-</span>logging kubectl apply <span class="sy0">-</span>f elasticsearch_statefulset<span class="sy0">.</span>yaml <span class="sy0">-</span>n kube<span class="sy0">-</span>logging kubectl apply <span class="sy0">-</span>f elasticsearch_svc<span class="sy0">.</span>yaml <span class="sy0">-</span>n kube<span class="sy0">-</span>logging kubectl apply <span class="sy0">-</span>f fluentd<span class="sy0">-</span>daemonset<span class="sy0">.</span>yaml <span class="sy0">-</span>n kube<span class="sy0">-</span>logging kubectl apply <span class="sy0">-</span>f kibana<span class="sy0">.</span>yaml <span class="sy0">-</span>n kube<span class="sy0">-</span>logging kubectl apply <span class="sy0">-</span>f kibana_ingress<span class="sy0">.</span>yaml <span class="sy0">-</span>n kube<span class="sy0">-</span>logging все контейнеры запускаются на worker<span class="sy0">-</span>нодах<span class="sy0">,</span> следуя из этого прописываем доменное имя kibana<span class="sy0">.</span>cluster<span class="sy0">.</span>local в хостах и назначаем ip<span class="sy0">-</span>адрес любой worker<span class="sy0">-</span>ноды<span class="sy0">.</span> |
================================================
EFK - с томами на nfs шаре
Elasticsearch — распределенный и масштабируемый механизм поиска в реальном времени, поддерживающий полнотекстовый и структурированный поиск, а также аналитику. Он обычно используется для индексации больших журналов и поиска в них данных, но также его можно использовать и для поиска во многих различных видах документов.
Elasticsearch обычно развертывается вместе с Kibana, мощным интерфейсом визуализации данных, который выступает как панель управления Elasticsearch. Kibana позволяет просматривать данные журналов Elasticsearch через веб-интерфейс и создавать информационные панели и запросы для быстрого получения ответов на вопросы и аналитических данных по вашим приложениям Kubernetes.
мы используем Fluentd для сбора данных журнала и их преобразования и отправки на сервер Elasticsearch. Fluentd — популярный сборщик данных с открытым исходным кодом, который мы настроим на узлах Kubernetes для отслеживания файлов журнала контейнеров, фильтрации и преобразования данных журнала и их доставки в кластер Elasticsearch, где они будут индексироваться и храниться.
Для начала мы настроим и запустим масштабируемый кластер Elasticsearch, а затем создадим службу и развертывание Kibana в Kubernetes. В заключение мы настроим Fluentd как DaemonSet, который будет запускаться на каждом рабочем узле Kubernetes.
Узнаём имя кластера(потом понадобится)
|
1 2 3 |
[root@minikub efk]# kubectl config view -o jsonpath='{"Cluster name\tServer\n"}{range .clusters[*]}{.name}{"\t"}{.cluster.server}{"\n"}{end}' Cluster name Server <strong>minikube </strong> https://192.168.1.120:8443 |
Шаг 1 — Создание пространства имен
Прежде чем разворачивать кластер Elasticsearch, мы создадим пространство имен, куда установим весь инструментарий ведения журналов. Kubernetes позволяет отделять объекты, работающие в кластере, с помощью виртуального абстрагирования кластеров через пространства имен. В этом обучающем модуле мы создадим пространство имен efk, куда установим компоненты комплекса EFK. Это пространство имен также позволит нам быстро очищать и удалять комплекс журналов без потери функциональности кластера Kubernetes.
Для начала исследуйте существующие пространства имен в вашем кластере с помощью команды kubectl:
|
1 2 3 4 5 6 7 8 |
[root@minikub ~]# kubectl get namespaces NAME STATUS AGE default Active 229d kube-node-lease Active 229d kube-public Active 229d kube-system Active 229d postgres Active 44d terminal-soft Active 46d |
Пространство имен default содержит объекты, которые создаются без указания пространства имен. Пространство имен kube-system содержит объекты, созданные и используемые системой Kubernetes, в том числе kube-dns, kube-proxy и kubernetes-dashboard. Это пространство имен лучше регулярно очищать и не засорять его рабочими задачами приложений и инструментария.
Пространство имен kube-public — это еще одно автоматически создаваемое пространство имен, которое можно использовать для хранения объектов, которые вы хотите сделать доступными и читаемыми во всем кластере, в том числе для пользователей, которые не прошли аутентификацию.
Для создания пространства имен efk откройте файл namespace.yml
[codesyntax lang="php"]
|
1 2 3 4 |
kind: Namespace apiVersion: v1 metadata: name: efk |
[/codesyntax]
Затем сохраните и закройте файл.
Здесь мы зададим вид объекта Kubernetes как объект Namespace. Чтобы узнать больше об объектах Namespace, ознакомьтесь с кратким обзором пространств имен в официальной документации по Kubernetes. Также мы зададим версию Kubernetes API, используемую для создания объекта (v1), и присвоим ему имя efk
Шаг 2 — Создание набора Elasticsearch StatefulSet
Мы создали пространство имен для нашего комплекса ведения журналов, и теперь можем начать развертывание его компонентов. Вначале мы развернем кластер Elasticsearch из 3 узлов.
мы будем использовать 3 пода Elasticsearch, чтобы избежать проблемы «разделения мозга», которая встречается в сложных кластерах с множеством узлов и высоким уровнем доступности. Такое «разделение мозга» происходит, когда несколько узлов не могут связываться с другими узлами, и в связи с этим выбирается несколько отдельных основных узлов. В случае с 3 узлами, если один узел временно отключается от кластера, остальные два узла могут выбрать новый основной узел, и кластер будет продолжать работу, пока последний узел будет пытаться снова присоединиться к нему. Дополнительную информацию можно найти в документах «Новая эпоха координации кластеров в Elasticsearch» и «Конфигурации голосования».
Создание службы без главного узла
Для начала мы создадим службу Kubernetes без главного узла с именем elasticsearch, которая будет определять домен DNS для 3 подов. Служба без главного узла не выполняет балансировку нагрузки и не имеет статического IP-адреса. Дополнительную информацию о службах без главного узла можно найти в официальной документации по Kubernetes.
Откройте файл с именем elasticsearch_service.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
kind: Service apiVersion: v1 metadata: name: elasticsearch namespace: efk labels: app: elasticsearch spec: selector: app: elasticsearch clusterIP: None ports: - port: 9200 name: rest - port: 9300 name: inter-node |
[/codesyntax]
Затем сохраните и закройте файл.
Мы определяем службу с именем elasticsearch в пространстве имен efk и присваиваем ей ярлык app: elasticsearch. Затем мы задаем для .spec.selector значение app: elasticsearch, чтобы служба выбирала поды с ярлыком app: elasticsearch. Когда мы привязываем Elasticsearch StatefulSet к этой службе, служба возвращает записи DNS A, которые указывают на поды Elasticsearch с ярлыком app: elasticsearch.
Затем мы задаем параметр clusterIP: None, который делает эту службу службой без главного узла. В заключение мы определяем порты 9200 и 9300, которые используются для взаимодействия с REST API и для связи между узлами соответственно.
Мы настроили службу без главного узла и стабильный домен .elasticsearch.efk.svc.minikube для наших подов. Теперь мы можем создать набор StatefulSet.
Создание набора StatefulSet
Набор Kubernetes StatefulSet позволяет назначать подам стабильный идентификатор и предоставлять им стабильное и постоянное хранилище. Elasticsearch требуется стабильное хранилище, чтобы его данные сохранялись при перезапуске и изменении планировки подов. Дополнительную информацию о рабочей задаче StatefulSet можно найти на странице Statefulsets в документации по Kubernetes.
смотрим имя нашего провиженера(provisioner)
|
1 2 3 4 |
[root@minikub efk]# kubectl get storageclasses.storage.k8s.io NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE <strong>managed-nfs-storage</strong> test.ru/nfs Retain Immediate false 45d standard (default) k8s.io/minikube-hostpath Delete Immediate false 229d |
Откройте файл с именем elasticsearch_statefulset.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
apiVersion: apps/v1 kind: StatefulSet metadata: name: es-cluster namespace: efk spec: serviceName: elasticsearch replicas: 3 selector: matchLabels: app: elasticsearch template: metadata: labels: app: elasticsearch spec: containers: - name: elasticsearch image: docker.elastic.co/elasticsearch/elasticsearch:7.10.0 resources: limits: cpu: 1000m requests: cpu: 100m ports: - containerPort: 9200 name: rest protocol: TCP - containerPort: 9300 name: inter-node protocol: TCP volumeMounts: - name: data-nfs-shara mountPath: /usr/share/elasticsearch/data env: - name: cluster.name value: minikube - name: node.name valueFrom: fieldRef: fieldPath: metadata.name - name: discovery.seed_hosts value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch" - name: cluster.initial_master_nodes value: "es-cluster-0,es-cluster-1,es-cluster-2" - name: ES_JAVA_OPTS value: "-Xms512m -Xmx512m" initContainers: - name: fix-permissions image: busybox command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"] securityContext: privileged: true volumeMounts: - name: data-nfs-shara mountPath: /usr/share/elasticsearch/data - name: increase-vm-max-map image: busybox command: ["sysctl", "-w", "vm.max_map_count=262144"] securityContext: privileged: true - name: increase-fd-ulimit image: busybox command: ["sh", "-c", "ulimit -n 65536"] securityContext: privileged: true volumeClaimTemplates: - metadata: name: data-nfs-shara labels: app: elasticsearch spec: accessModes: [ "ReadWriteMany" ] storageClassName: <strong>managed-nfs-storage</strong> resources: requests: storage: 1Gi |
[/codesyntax]
рассмотрим каждый блок в отдельности:
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
apiVersion: apps/v1 kind: StatefulSet metadata: name: es-cluster namespace: efk spec: serviceName: elasticsearch replicas: 3 selector: matchLabels: app: elasticsearch template: metadata: labels: app: elasticsearch |
[/codesyntax]
.
В этом блоке мы определяем объект StatefulSet под названием es-cluster в пространстве имен efk. Затем мы связываем его с ранее созданной службой elasticsearch, используя поле serviceName. За счет этого каждый под набора StatefulSet будет доступен по следующему адресу DNS: es-cluster-[0,1,2].elasticsearch.efk.svc.minikube, где [0,1,2] соответствует назначенному номеру пода в виде обычного целого числа.
Мы задали 3 копии (пода) и установили для селектора matchLabels значение app: elasticseach, которое мы также отразим в разделе .spec.template.metadata. Поля .spec.selector.matchLabels и .spec.template.metadata.labels должны совпадать.
Теперь мы можем перейти к спецификации объекта.
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
. . . spec: containers: - name: elasticsearch image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0 resources: limits: cpu: 1000m requests: cpu: 100m ports: - containerPort: 9200 name: rest protocol: TCP - containerPort: 9300 name: inter-node protocol: TCP volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data env: - name: cluster.name value: minikube - name: node.name valueFrom: fieldRef: fieldPath: metadata.name - name: discovery.seed_hosts value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch" - name: cluster.initial_master_nodes value: "es-cluster-0,es-cluster-1,es-cluster-2" - name: ES_JAVA_OPTS value: "-Xms512m -Xmx512m" |
[/codesyntax]
Здесь мы определяем поды в наборе StatefulSet. Мы присвоим контейнерам имя elasticsearch и выберем образ Docker docker.elastic.co/elasticsearch/elasticsearch:7.2.0. Сейчас вы можете изменить метку образа, чтобы она соответствовала вашему собственному образу Elasticsearch или другой версии образа.
Мы используем поле resources, чтобы указать, что контейнеру требуется всего гарантировать всего десятую часть ресурсов vCPU с возможностью увеличения загрузки до 1 vCPU (что ограничивает использование ресурсов подом при первоначальной обработке большого объема данных или при пиковой нагрузке). Вам следует изменить эти значения в зависимости от ожидаемой нагрузки и доступных ресурсов. Дополнительную информацию о запросах ресурсов и ограничениях можно найти в официальной документации по Kubernetes.
Мы откроем и назовем порты 9200 и 9300 для REST API и связи между узлами соответственно. Мы зададим volumeMount с именем data, который будет монтировать постоянный том с именем data в контейнер по пути /usr/share/elasticsearch/data. Мы определим VolumeClaims для набора StatefulSet в другом блоке YAML позднее.
В заключение мы зададим в контейнере несколько переменных среды:
cluster.name: имя кластера Elasticsearch, efknode.name: имя узла, которое мы устанавливаем как значение поля.metadata.nameс помощьюvalueFrom. Оно разрешается какes-cluster-[0,1,2]в зависимости от назначенного узлу порядкового номера.discovery.seed_hosts: это поле использует список потенциальных главных узлов в кластере, инициирующем процесс обнаружения узлов. Поскольку в этом обучающем модуле мы уже настроили службу без главного узла, наши поды имеют домены в формеes-cluster-[0,1,2].elasticsearch.efk.svc.minikube, так что мы зададим соответствующее значение для этой переменной. Используя разрешение DNS в локальном пространстве имен Kubernetes мы можем сократить это доes-cluster-[0,1,2].elasticsearch. Дополнительную информацию об обнаружении Elasticsearch можно найти в официальной документации по Elasticsearch.cluster.initial_master_nodes: в этом поле также задается список потенциальных главных узлов, которые будут участвовать в процессе выбора главного узла. Обратите внимание, что для этого поля узлы нужно указывать по имениnode.name, а не по именам хостов.ES_JAVA_OPTS: здесь мы задаем значение-Xms512m -Xmx512m, которое предписывает JVM использовать минимальный и максимальный размер выделения памяти 512 МБ. Вам следует настроить эти параметры в зависимости от доступности ресурсов и потребностей вашего кластера. Дополнительную информацию можно найти в разделе «Настройка размера выделяемой памяти».
Следующий блок, который мы будем вставлять, выглядит следующим образом:
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
. . . initContainers: - name: fix-permissions image: busybox command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"] securityContext: privileged: true volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data - name: increase-vm-max-map image: busybox command: ["sysctl", "-w", "vm.max_map_count=262144"] securityContext: privileged: true - name: increase-fd-ulimit image: busybox command: ["sh", "-c", "ulimit -n 65536"] securityContext: privileged: true |
[/codesyntax]
В этом блоке мы определяем несколько контейнеров инициализации, которые запускаются до главного контейнера приложения elasticsearch. Каждый из этих контейнеров инициализации выполняется до конца в заданном порядке. Дополнительную информацию о контейнерах инициализации можно найти в официальной документации по Kubernetes.
Первый такой контейнер с именем fix-permissions запускает команду chown для смены владельца и группы каталога данных Elasticsearch на 1000:1000, UID польздователя Elasticsearch. По умолчанию Kubernetes монтирует каталог данных как root, что делает его недоступным для Elasticsearch. Дополнительную информацию об этом шаге можно найти в документации по Elasticsearch «Замечания по использованию в производстве и значения по умолчанию».
Второй контейнер с именем increase-vm-max-map запускает команду для увеличения предельного количества mmap в операционной системе, которое по умолчанию может быть слишком низким, в результате чего могут возникать ошибки памяти. Дополнительную информацию об этом шаге можно найти в официальной документации по Elasticsearch.
Следующим запускается контейнер инициализации increase-fd-ulimit, который запускает команду ulimit для увеличения максимального количества дескрипторов открытых файлов. Дополнительную информацию об этом шаге можно найти в документации по Elasticsearch «Замечания по использованию в производстве и значения по умолчанию».
Примечание. В документе «Замечания по использованию в производстве и значения по умолчанию» для Elasticsearch также указывается возможность отключения подкачки для повышения производительности. В зависимости от вида установки Kubernetes и провайдера, подкачка может быть уже отключена. Чтобы проверить это, выполните команду exec в работающем контейнере и запустите cat /proc/swaps для вывода активных устройств подкачки. Если этот список пустой, подкачка отключена.
Мы определили главный контейнер приложений и контейнеры инициализации, которые будут запускаться перед ним для настройки ОС контейнера. Теперь мы можем доставить в наш файл определения объекта StatefulSet заключительную часть: блок volumeClaimTemplates.
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 |
. . . volumeClaimTemplates: - metadata: name: data-nfs-shara labels: app: elasticsearch spec: accessModes: [ "ReadWriteOnce" ] storageClassName: managed-nfs-storage resources: requests: storage: 100Gi |
[/codesyntax]
В этом блоке мы определяем для StatefulSet шаблоны volumeClaimTemplates. Kubernetes использует эти настройки для создания постоянных томов для подов. В приведенном выше блоке мы использовали имя data-nfs-shara (это имя, на которое мы уже ссылались в определении volumeMounts), и присвоили ему тот же ярлык app: elasticsearch, что и для набора StatefulSet.
Затем мы задаем для него режим доступа ReadWriteOnce, и это означает, что его может монтировать для чтения и записи только один узел. В этом обучающем модуле мы определяем класс хранения managed-nfs-storage. Вам следует изменить это значение в зависимости от того, где вы запускаете свой кластер Kubernetes. Дополнительную информацию можно найти в документации по постоянным томам.
В заключение мы укажем, что каждый постоянный том должен иметь размер 100 ГиБ. Вам следует изменить это значение в зависимости от производственных потребностей.
После развертывания всех подов вы можете использовать запрос REST API, чтобы убедиться, что кластер Elasticsearch функционирует нормально.
Для этого вначале нужно перенаправить локальный порт 9200 на порт 9200 одного из узлов Elasticsearch (es-cluster-0) с помощью команды kubectl port-forward:
kubectl port-forward es-cluster-0 9200:9200 --namespace=efk
В отдельном окне терминала отправьте запрос curl к REST API:
curl http://localhost:9200/_cluster/state?pretty
Результат должен выглядеть следующим образом:
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
{ "cluster_name" : "minikube", "compressed_size_in_bytes" : 348, "cluster_uuid" : "QD06dK7CQgids-GQZooNVw", "version" : 3, "state_uuid" : "mjNIWXAzQVuxNNOQ7xR-qg", "master_node" : "IdM5B7cUQWqFgIHXBp0JDg", "blocks" : { }, "nodes" : { "u7DoTpMmSCixOoictzHItA" : { "name" : "es-cluster-1", "ephemeral_id" : "ZlBflnXKRMC4RvEACHIVdg", "transport_address" : "10.244.8.2:9300", "attributes" : { } }, "IdM5B7cUQWqFgIHXBp0JDg" : { "name" : "es-cluster-0", "ephemeral_id" : "JTk1FDdFQuWbSFAtBxdxAQ", "transport_address" : "10.244.44.3:9300", "attributes" : { } }, "R8E7xcSUSbGbgrhAdyAKmQ" : { "name" : "es-cluster-2", "ephemeral_id" : "9wv6ke71Qqy9vk2LgJTqaA", "transport_address" : "10.244.40.4:9300", "attributes" : { } } }, ... |
[/codesyntax]
Это показывает, что журналы minikube нашего кластера Elasticsearch успешно созданы с 3 узлами: es-cluster-0, es-cluster-1 и es-cluster-2. В качестве главного узла выступает узел es-cluster-0.
Теперь ваш кластер Elasticsearch запущен, и вы можете перейти к настройке на нем клиентского интерфейса Kibana.
Шаг 3 — Создание развертывания и службы Kibana
Чтобы запустить Kibana в Kubernetes, мы создадим службу с именем kibana, а также развертывание, состоящее из одной копии пода. Вы можете масштабировать количество копий в зависимости от ваших производственных потребностей и указывать тип LoadBalancer, чтобы служба запрашивала балансировку нагрузки на подах развертывания.
В этом случае мы создадим службу и развертывание в одном и том же файле. Откройте файл с именем kibana.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
apiVersion: v1 kind: Service metadata: name: kibana namespace: efk labels: app: kibana spec: ports: - port: 5601 selector: app: kibana --- apiVersion: apps/v1 kind: Deployment metadata: name: kibana namespace: efk labels: app: kibana spec: replicas: 1 selector: matchLabels: app: kibana template: metadata: labels: app: kibana spec: containers: - name: kibana image: docker.elastic.co/kibana/kibana:7.10.0 resources: limits: cpu: 1000m requests: cpu: 100m env: - name: ELASTICSEARCH_URL value: http://elasticsearch:9200 ports: - containerPort: 5601 |
[/codesyntax]
Затем сохраните и закройте файл.
В этой спецификации мы определили службу с именем kibana в пространстве имен efk и присвоить ему ярлык app: kibana.
Также мы указали, что она должна быть доступна на порту 5601, и использовали ярлык app: kibana для выбора целевых подов службы.
В спецификации Deployment мы определим развертывание с именем kibana и укажем, что нам требуется 1 копия пода.
Мы будем использовать образ docker.elastic.co/kibana/kibana:7.2.0. Сейчас вы можете заменить этот образ на собственный частный или публичный образ Kibana, который вы хотите использовать.
Мы укажем, что нам требуется гарантировать для пода не менее 0.1 vCPU и не более 1 vCPU при пиковой нагрузке. Вам следует изменить эти значения в зависимости от ожидаемой нагрузки и доступных ресурсов.
Теперь мы используем переменную среды ELASTICSEARCH_URL для установки конечной точки и порта для кластера Elasticsearch. При использовании Kubernetes DNS эта конечная точка соответствует названию службы elasticsearch. Этот домен разрешится в список IP-адресов для 3 подов Elasticsearch. Дополнительную информацию о Kubernetes DNS можно получить в документе DNS для служб и подов.
Наконец мы настроим для контейнера Kibana порт 5601, куда служба kibana будет перенаправлять запросы.
теперь посмотрим ingres для кибана:
kibana_ingress.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: kibana namespace: efk annotations: kubernetes.io/ingress.class: nginx spec: rules: - host: efk.test.ru http: paths: - backend: serviceName: kibana servicePort: 5601 |
[/codesyntax]
Шаг 4 — Создание набора демонов Fluentd
мы настроим Fluentd как набор демонов. Это тип рабочей задачи Kubernetes, запускающий копию указанного пода на каждом узле в кластере Kubernetes. Используя контроллер набора демонов, мы развернем под агента регистрации данных Fluentd на каждом узле нашего кластера. Дополнительную информацию об архитектуре регистрации данных можно найти в документе «Использование агента регистрации данных узлов» в официальной документации по Kubernetes.
В Kubernetes приложения в контейнерах записывают данные в stdout и stderr, и их потоки регистрируемых данных записываются и перенаправляются в файлы JSON на узлах. Под Fluentd отслеживает эти файлы журналов, фильтрует события журналов, преобразует данные журналов и отправляет их на сервенюу часть регистрации данных Elasticsearch, которую мы развернули на шаге 2.
Помимо журналов контейнеров, агент Fluentd также отслеживает журналы системных компонентов Kubernetes, в том числе журналы kubelet, kube-proxy и Docker. Полный список источников, отслеживаемых агентом регистрации данных Fluentd, можно найти в файле kubernetes.conf, используемом для настройки агента регистрации данных. Дополнительную информацию по регистрации данных в кластерах Kubernetes можно найти в документе «Регистрация данных на уровне узлов» в официальной документации по Kubernetes.
Для начала откройте файл fluentd-daemonset.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
apiVersion: v1 kind: ServiceAccount metadata: name: fluentd namespace: efk labels: app: fluentd --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: fluentd labels: app: fluentd rules: - apiGroups: - "" resources: - pods - namespaces verbs: - get - list - watch --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd roleRef: kind: ClusterRole name: fluentd apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: fluentd namespace: efk --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd namespace: efk labels: app: fluentd spec: selector: matchLabels: app: fluentd template: metadata: labels: app: fluentd spec: serviceAccount: fluentd serviceAccountName: fluentd # tolerations: # - key: node-role.kubernetes.io/master # effect: NoSchedule containers: - name: fluentd image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1 env: - name: FLUENT_ELASTICSEARCH_HOST value: "elasticsearch.efk.svc.minikube" - name: FLUENT_ELASTICSEARCH_PORT value: "9200" - name: FLUENT_ELASTICSEARCH_SCHEME value: "http" - name: FLUENTD_SYSTEMD_CONF value: disable resources: limits: memory: 512Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers |
[/codesyntax]
опишем каждый блок:
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 |
apiVersion: v1 kind: ServiceAccount metadata: name: fluentd namespace: efk labels: app: fluentd |
[/codesyntax]
Здесь мы создаем служебную учетную запись fluentd, которую поды Fluentd будут использовать для доступа к Kubernetes API. Мы создаем ее в пространстве имен efk и снова присваиваем ей ярлык app: fluentd. Дополнительную информацию о служебных учетных записях в Kubernetes можно найти в документе «Настройка служебных учетных записей для подов» в официальной документации по Kubernetes.
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
. . . --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: fluentd labels: app: fluentd rules: - apiGroups: - "" resources: - pods - namespaces verbs: - get - list - watch |
[/codesyntax]
Здесь мы определяем блок ClusterRole с именем fluentd, которому мы предоставляем разрешения get, list и watch для объектов pods и namespaces. ClusterRoles позволяет предоставлять доступ к ресурсам в кластере Kubernetes, в том числе к узлам. Дополнительную информацию о контроле доступа на основе ролей и ролях кластеров можно найти в документе «Использование авторизации RBAC» в официальной документации Kubernetes.
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
. . . --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd roleRef: kind: ClusterRole name: fluentd apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: fluentd namespace: efk |
[/codesyntax]
В этом блоке мы определяем объект ClusterRoleBinding с именем fluentd, которй привязывает роль кластера fluentd к служебной учетной записи fluentd. Это дает служебной учетной записи fluentd разрешения, заданные для роли кластера fluentd.
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 |
--- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd namespace: efk labels: app: fluentd |
[/codesyntax]
Здесь мы определяем набор демонов с именем fluentd в пространстве имен efk и назначаем ему ярлык app: fluentd.
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
. . . spec: selector: matchLabels: app: fluentd template: metadata: labels: app: fluentd spec: serviceAccount: fluentd serviceAccountName: fluentd tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule containers: - name: fluentd image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1 env: - name: FLUENT_ELASTICSEARCH_HOST value: "elasticsearch.efk.svc.minikube" - name: FLUENT_ELASTICSEARCH_PORT value: "9200" - name: FLUENT_ELASTICSEARCH_SCHEME value: "http" - name: FLUENTD_SYSTEMD_CONF value: disable |
[/codesyntax]
Здесь мы сопоставляем ярлык app: fluentd, определенный в .metadata.labels и назначаем для набора демонов служебную учетную запись fluentd. Также мы выбираем app: fluentd как поды, управляемые этим набором демонов.
Затем мы определяем допуск NoSchedule для соответствия эквивалентному вызову в главных узлах Kubernetes. Это гарантирует, что набор демонов также будет развернут на главных узлах Kubernetes. Если вы не хотите запускать под Fluentd на главных узлах, удалите этот допуск. Дополнительную информацию о вызовах и допусках Kubernetes можно найти в разделе «Вызовы и допуски» в официальной документации по Kubernetes.
Теперь мы начнем определять контейнер пода с именем fluentd.
Мы используем официальный образ v1.4.2 Debian от команды, обслуживающей Fluentd. Если вы хотите использовать свой частный или публичный образ Fluentd или использовать другую версию образа, измените тег image в спецификации контейнера. Файл Dockerfile и содержание этого образа доступны в репозитории fluentd-kubernetes-daemonset на Github.
Теперь мы настроим Fluentd с помощью нескольких переменных среды:
FLUENT_ELASTICSEARCH_HOST: мы настроим службу Elasticsearch без главных узлов, которую мы определили ранее:elasticsearch.efk.svc.minikube. Это разрешается список IP-адресов для 3 подов Elasticsearch. Скорее всего, реальный хост Elasticsearch будет первым IP-адресом, который будет выведен в этом списке. Для распределения журналов в этом кластере вам потребуется изменить конфигурацию плагина вывода Fluentd Elasticsearch. Дополнительную информацию об этом плагине можно найти в документе «Плагин вывода Elasticsearch».FLUENT_ELASTICSEARCH_PORT: в этом параметре мы задаем ранее настроенный портElasticsearch 9200.FLUENT_ELASTICSEARCH_SCHEME: мы задаем для этого параметра значениеhttp.FLUENTD_SYSTEMD_CONF: мы задаем для этого параметра значениеdisable, чтобы подавить выводsystemd, который не настроен в контейнере.
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
. . . resources: limits: memory: 512Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers |
[/codesyntax]
Здесь мы указываем предельный объем памяти 512 МиБ в поде FluentD и гарантируем выделение 0,1 vCPU и 200 МиБ памяти. Вы можете настроить эти ограничения ресурсов и запросы в зависимости от ожидаемого объема журнала и доступных ресурсов.
Затем мы смонтируем пути хостов /var/log и /var/lib/docker/containers в контейнер, используя varlog и varlibdockercontainers volumeMounts. Эти тома определяются в конце блока.
Последний параметр, который мы определяем в этом блоке, — это параметр terminationGracePeriodSeconds, дающий Fluentd 30 секунд для безопасного выключения при получении сигнала SIGTERM. После 30 секунд контейнеры получают сигнал SIGKILL. Значение по умолчанию для terminationGracePeriodSeconds составляет 30 с, так что в большинстве случаев этот параметр можно пропустить. Дополнительную информацию о безопасном прекращении рабочих задач Kubernetes можно найти в документе Google «Лучшие практики Kubernetes: осторожное прекращение работы».
теперь можно запускать:
[root@minikub efk]# kubectl apply -f namespace.yml -f elasticsearch_service.yaml -f elasticsearch_statefulset.yaml -f fluentd-daemonset.yaml -f kibana_ingress.yaml -f kibana.yaml
namespace/efk created
service/elasticsearch created
statefulset.apps/es-cluster created
serviceaccount/fluentd created
clusterrole.rbac.authorization.k8s.io/fluentd created
clusterrolebinding.rbac.authorization.k8s.io/fluentd created
daemonset.apps/fluentd created
ingress.extensions/kibana created
service/kibana created
deployment.apps/kibana created
====================================================================================================
Мой рабочий вариант.
тут будет для каждого неймспейса свой индекс. Шара висит на NFS
cat namespace.yml
[codesyntax lang="php"]
|
1 2 3 4 5 |
kind: Namespace apiVersion: v1 metadata: name: efk |
[/codesyntax]
cat elasticsearch_service.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
kind: Service apiVersion: v1 metadata: name: elasticsearch namespace: efk labels: app: elasticsearch spec: selector: app: elasticsearch clusterIP: None ports: - port: 9200 name: rest - port: 9300 name: inter-node |
[/codesyntax]
cat elasticsearch_statefulset.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
apiVersion: apps/v1 kind: StatefulSet metadata: name: es-cluster namespace: efk spec: serviceName: elasticsearch replicas: 3 selector: matchLabels: app: elasticsearch template: metadata: labels: app: elasticsearch spec: containers: - name: elasticsearch image: docker.elastic.co/elasticsearch/elasticsearch:7.10.0 resources: limits: cpu: 1000m requests: cpu: 100m ports: - containerPort: 9200 name: rest protocol: TCP - containerPort: 9300 name: inter-node protocol: TCP volumeMounts: - name: data-nfs-shara mountPath: /usr/share/elasticsearch/data env: - name: cluster.name value: test.local - name: node.name valueFrom: fieldRef: fieldPath: metadata.name - name: discovery.seed_hosts value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch" - name: cluster.initial_master_nodes value: "es-cluster-0,es-cluster-1,es-cluster-2" - name: ES_JAVA_OPTS value: "-Xms512m -Xmx512m" initContainers: - name: fix-permissions image: busybox command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"] securityContext: privileged: true volumeMounts: - name: data-nfs-shara mountPath: /usr/share/elasticsearch/data - name: increase-vm-max-map image: busybox command: ["sysctl", "-w", "vm.max_map_count=262144"] securityContext: privileged: true - name: increase-fd-ulimit image: busybox command: ["sh", "-c", "ulimit -n 65536"] securityContext: privileged: true volumeClaimTemplates: - metadata: name: data-nfs-shara labels: app: elasticsearch spec: accessModes: [ "ReadWriteMany" ] storageClassName: nfs-storageclass resources: requests: storage: 3Gi |
[/codesyntax]
cat fluentd-daemonset.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 |
apiVersion: v1 kind: ServiceAccount metadata: name: fluentd namespace: efk labels: app: fluentd --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: fluentd namespace: efk labels: app: fluentd rules: - apiGroups: - "" resources: - pods - namespaces verbs: - get - list - watch --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd roleRef: kind: ClusterRole name: fluentd apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: fluentd namespace: efk --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd namespace: efk labels: app: fluentd spec: selector: matchLabels: app: fluentd template: metadata: labels: app: fluentd spec: serviceAccount: fluentd serviceAccountName: fluentd # tolerations: # - key: node-role.kubernetes.io/master # effect: NoSchedule containers: - name: fluentd image: fluent/fluentd-kubernetes-daemonset:v1.11.5-debian-elasticsearch7-1.1 env: - name: FLUENT_ELASTICSEARCH_HOST value: "elasticsearch.efk.svc.test.local" - name: FLUENT_ELASTICSEARCH_PORT value: "9200" - name: FLUENT_ELASTICSEARCH_SCHEME value: "http" - name: FLUENTD_SYSTEMD_CONF value: disable - name: FLUENT_ELASTICSEARCH_SED_DISABLE value: "true" - name: FLUENT_ELASTICSEARCH_ENABLE_ILM value: "true" resources: limits: memory: 512Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: fluent-conf #имя нашего конфигмапа, созданного ранее. mountPath: /fluentd/etc/fluent.conf # путь по которому мы будем монтировать наш конфиг subPath: fluent.conf # не удаляет всё из директории а добавляет именно файл - name: fluentd-template-json mountPath: /fluentd/etc/fluentd-template.json subPath: fluentd-template.json terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: fluent-conf configMap: name: fluent-conf items: # указывает какой ключ должен монтироваться - key: fluent.conf # имя из конфигмапа path: fluent.conf - name: fluentd-template-json configMap: name: fluentd-template-json items: - key: fluentd-template.json path: fluentd-template.json |
[/codesyntax]
в этом конфиге мы сразу собираем логи нашего приложения идущие в stdout
в конфиге флюента в источнике указываем путь до директории с логами, и тегируем лог:
<source>
@type tail
path /var/log/containers/*terminal-soft*.log
tag terminal-soft
после указываем какое мы ищем совпадение:
<match terminal-soft**>
а так же как будут называться индексы в elasticsearch:
logstash_prefix test-index-terminal
cat fluentd-configmap_fluent_conf.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
apiVersion: v1 kind: ConfigMap metadata: name: fluent-conf namespace: efk data: fluent.conf: | @include "#{ENV['FLUENTD_SYSTEMD_CONF'] || 'systemd'}.conf" @include "#{ENV['FLUENTD_PROMETHEUS_CONF'] || 'prometheus'}.conf" @include kubernetes.conf @include conf.d/*.conf <source> @type tail path /var/log/containers/*terminal-soft*.log tag terminal-soft read_from_head true <parse> @type json time_format %Y-%m-%dT%H:%M:%S.%NZ </parse> </source> <match terminal-soft*> @type elasticsearch host elasticsearch port 9200 logstash_format true logstash_prefix terminal-soft #logstash_dateformat %Y.%m.%d rollover_index true enable_ilm true template_name terminal-soft_template template_file /fluentd/etc/fluentd-template.json application_name "terminal-soft" ilm_policy_id terminal-soft-policy type_name access_log tag_key @log_name flush_interval 1s <buffer> flush_thread_count "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_FLUSH_THREAD_COUNT'] || '8'}" flush_interval "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_FLUSH_INTERVAL'] || '5s'}" chunk_limit_size "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_CHUNK_LIMIT_SIZE'] || '2M'}" queue_limit_length "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_QUEUE_LIMIT_LENGTH'] || '32'}" retry_max_interval "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_RETRY_MAX_INTERVAL'] || '30'}" retry_forever true </buffer> </match> <match **> @type elasticsearch @id out_es @log_level debug include_tag_key true host "#{ENV['FLUENT_ELASTICSEARCH_HOST']}" port "#{ENV['FLUENT_ELASTICSEARCH_PORT']}" path "#{ENV['FLUENT_ELASTICSEARCH_PATH']}" scheme "#{ENV['FLUENT_ELASTICSEARCH_SCHEME'] || 'http'}" ssl_verify "#{ENV['FLUENT_ELASTICSEARCH_SSL_VERIFY'] || 'true'}" ssl_version "#{ENV['FLUENT_ELASTICSEARCH_SSL_VERSION'] || 'TLSv1'}" reload_connections "#{ENV['FLUENT_ELASTICSEARCH_RELOAD_CONNECTIONS'] || 'false'}" reconnect_on_error "#{ENV['FLUENT_ELASTICSEARCH_RECONNECT_ON_ERROR'] || 'true'}" reload_on_failure "#{ENV['FLUENT_ELASTICSEARCH_RELOAD_ON_FAILURE'] || 'true'}" log_es_400_reason "#{ENV['FLUENT_ELASTICSEARCH_LOG_ES_400_REASON'] || 'false'}" logstash_prefix "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_PREFIX'] || 'logstash'}" logstash_format "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_FORMAT'] || 'true'}" index_name "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_INDEX_NAME'] || 'logstash'}" type_name "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_TYPE_NAME'] || 'fluentd'}" <buffer> flush_thread_count "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_FLUSH_THREAD_COUNT'] || '8'}" flush_interval "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_FLUSH_INTERVAL'] || '5s'}" chunk_limit_size "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_CHUNK_LIMIT_SIZE'] || '2M'}" queue_limit_length "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_QUEUE_LIMIT_LENGTH'] || '32'}" retry_max_interval "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_RETRY_MAX_INTERVAL'] || '30'}" retry_forever true </buffer> </match> |
[/codesyntax]
в этом конфиге задаём шаблон для создания индексов, чтобы работал ролловер.
cat fluentd-configmap_template_json.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
apiVersion: v1 kind: ConfigMap metadata: name: fluentd-template-json namespace: efk data: fluentd-template.json: | { "index_patterns": ["terminal-soft*"], "settings": { "number_of_shards": 1, "number_of_replicas": 1, "index.lifecycle.name": "terminal-soft-policy", "index.lifecycle.rollover_alias": "terminal-soft" } } |
[/codesyntax]
cat kibana.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
apiVersion: v1 kind: Service metadata: name: kibana namespace: efk labels: app: kibana spec: ports: - port: 5601 selector: app: kibana --- apiVersion: apps/v1 kind: Deployment metadata: name: kibana namespace: efk labels: app: kibana spec: replicas: 1 selector: matchLabels: app: kibana template: metadata: labels: app: kibana spec: containers: - name: kibana image: docker.elastic.co/kibana/kibana:7.10.0 resources: limits: cpu: 1000m requests: cpu: 100m env: - name: ELASTICSEARCH_URL value: http://elasticsearch:9200 ports: - containerPort: 5601 |
[/codesyntax]
cat kibana_ingress.yaml
[codesyntax lang="php"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: kibana namespace: efk annotations: kubernetes.io/ingress.class: nginx spec: rules: - host: efk.prod.test.local http: paths: - backend: serviceName: kibana servicePort: 5601 |
[/codesyntax]
запускаем:
kubectl apply -f namespace.yml
kubectl apply -f .
далее заходим по ссылке:
http://efk.prod.test.local
переходим в создание патерна для индексов:
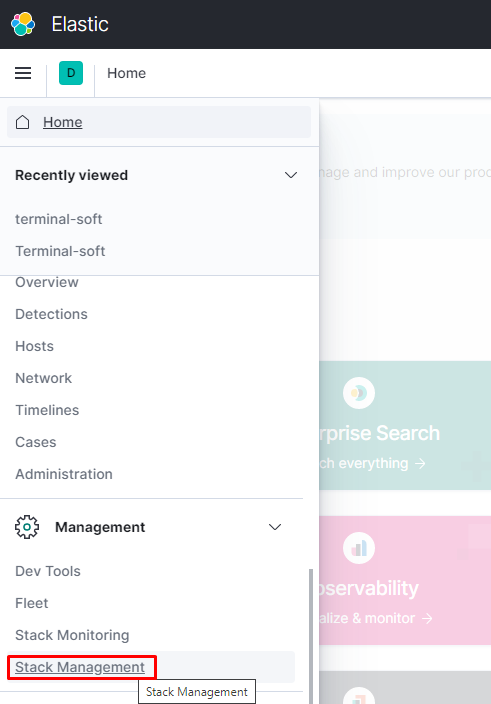
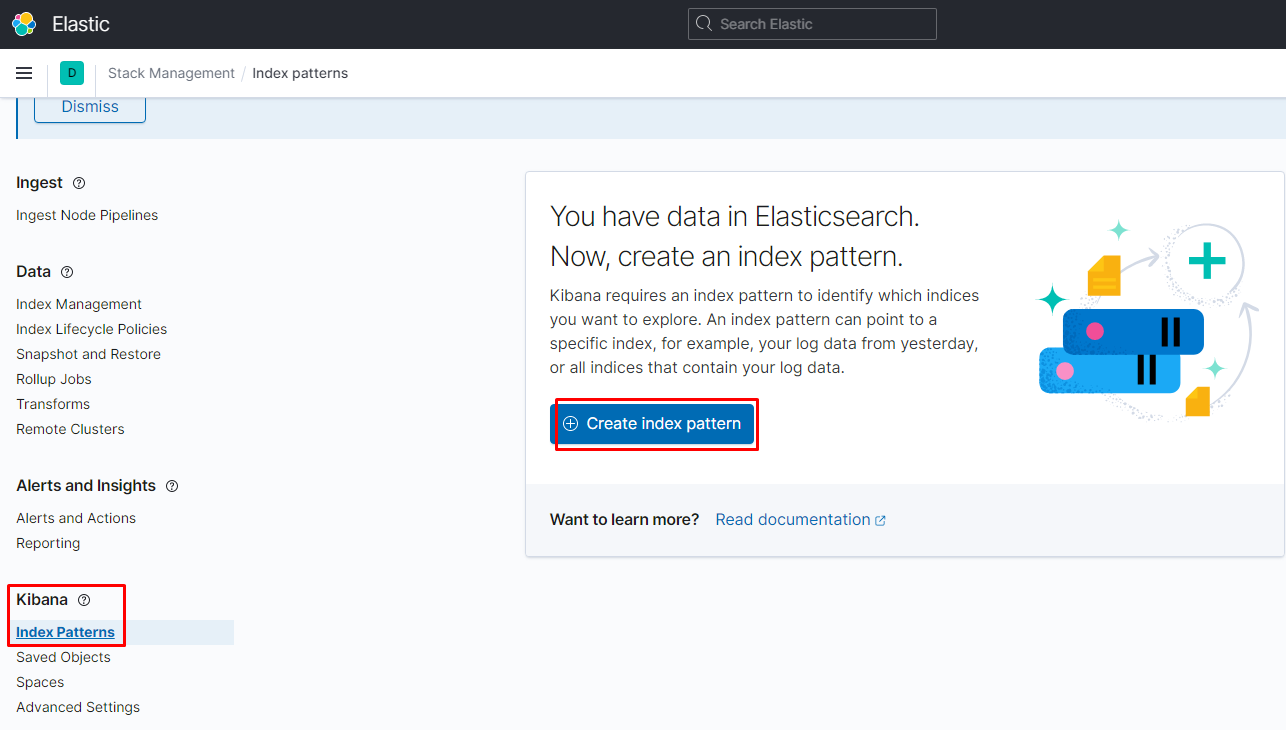
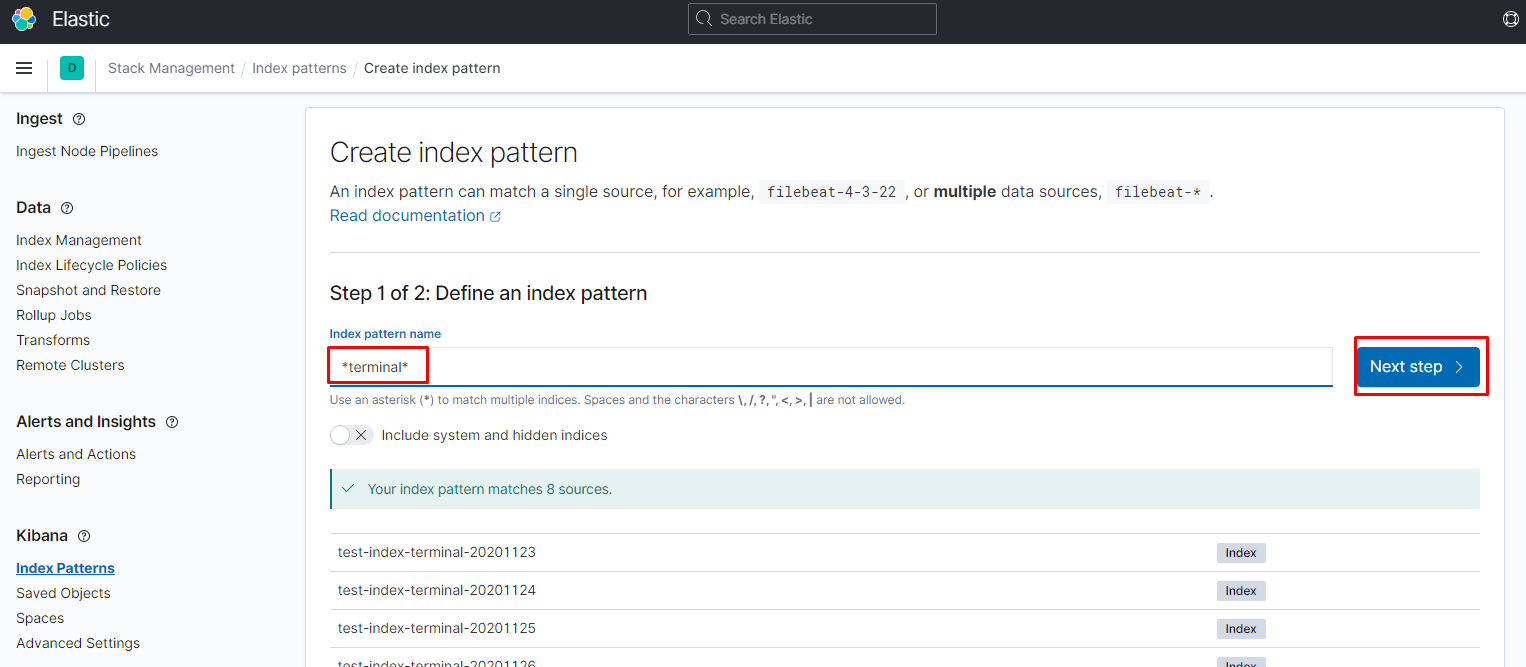
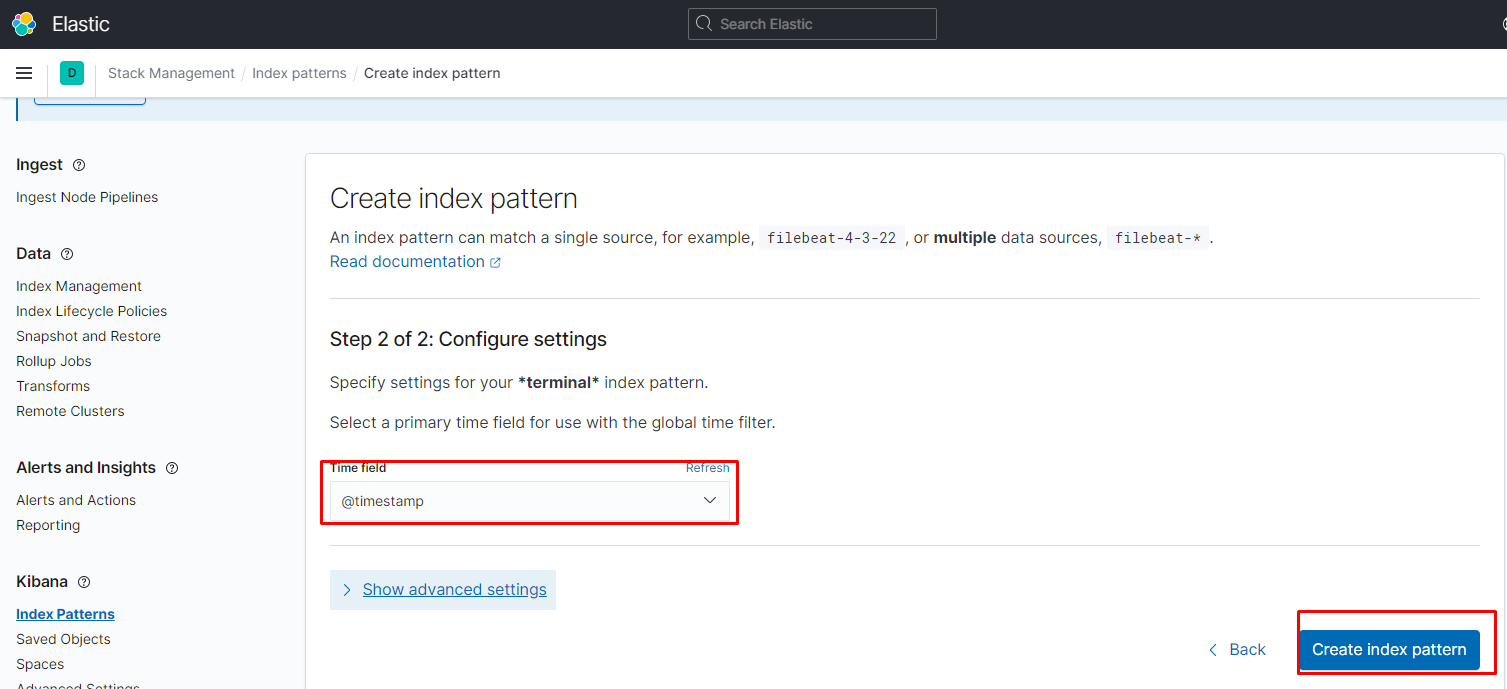
переходим в нужный нам патерн
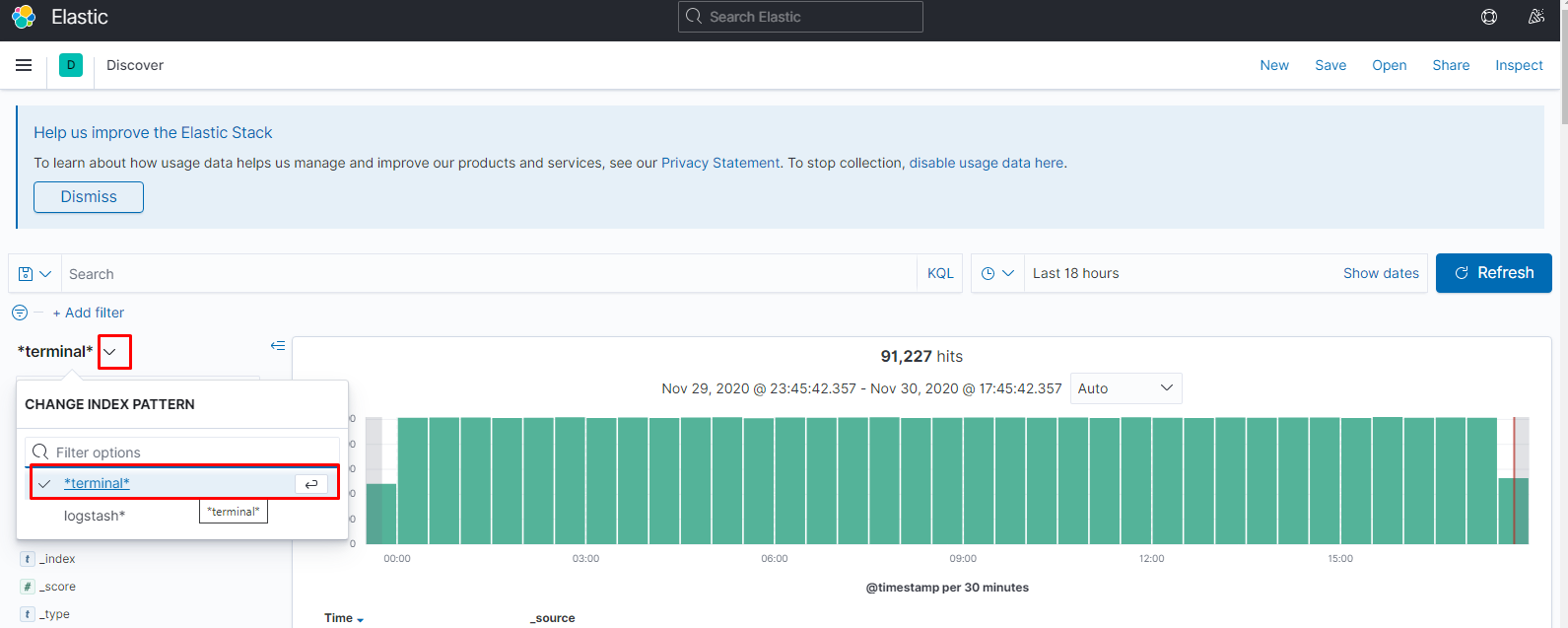
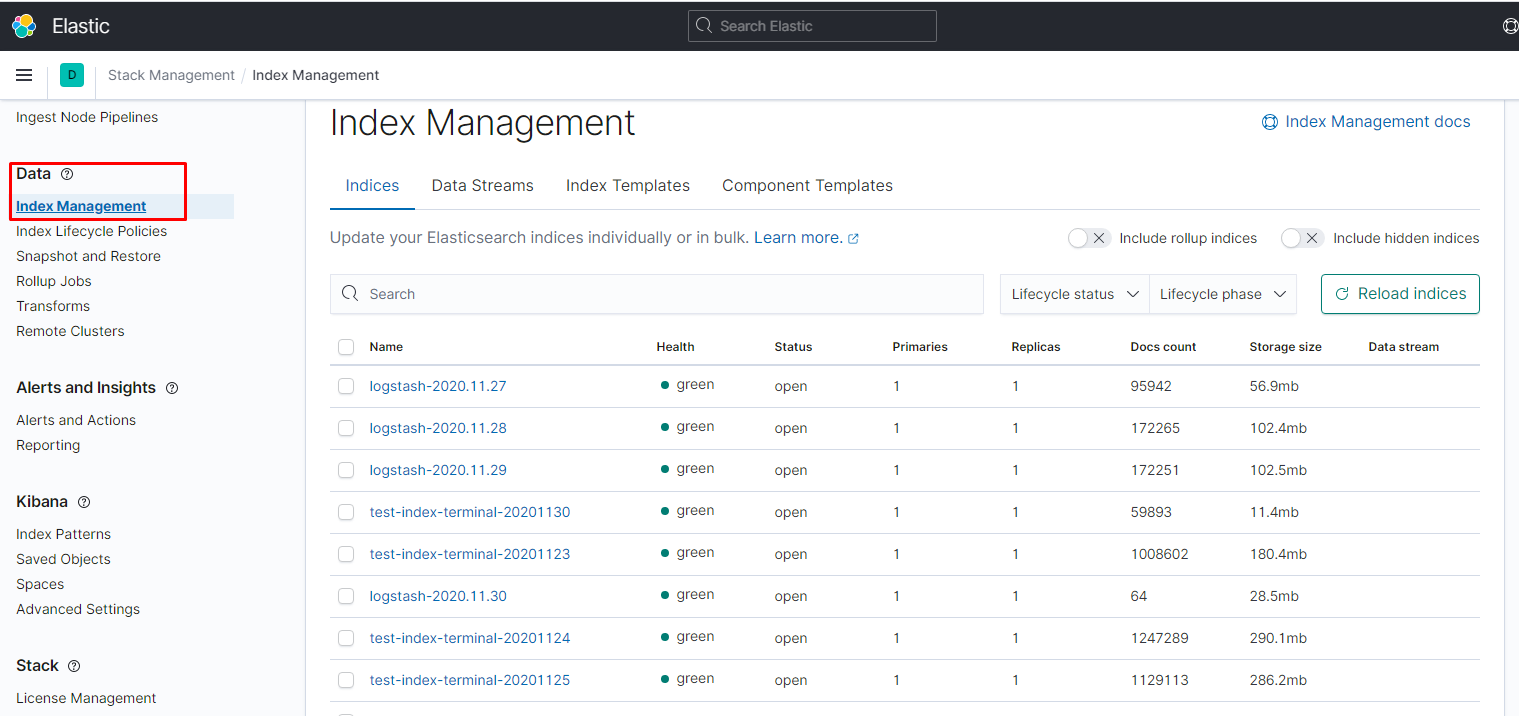
увидеть все индексы и их статус можно тут:
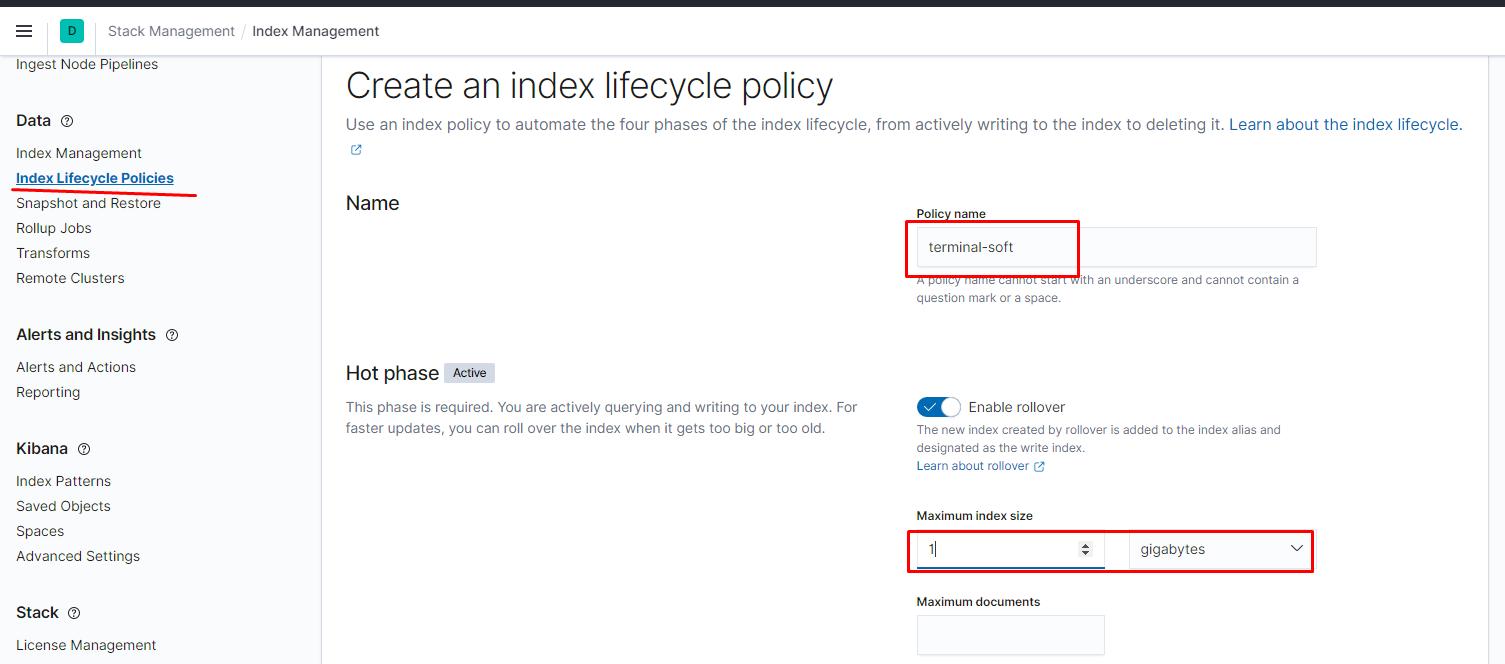
настроить их жизненный цикл можно следующим образом:
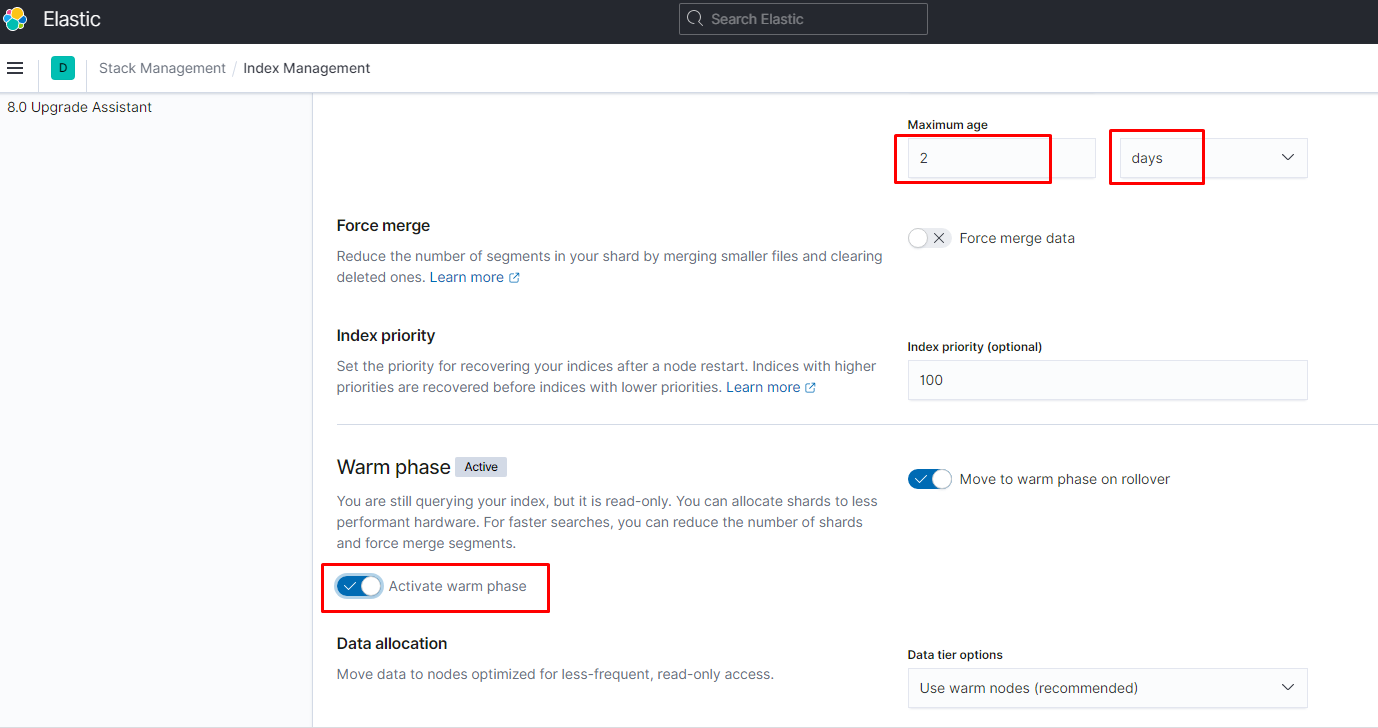
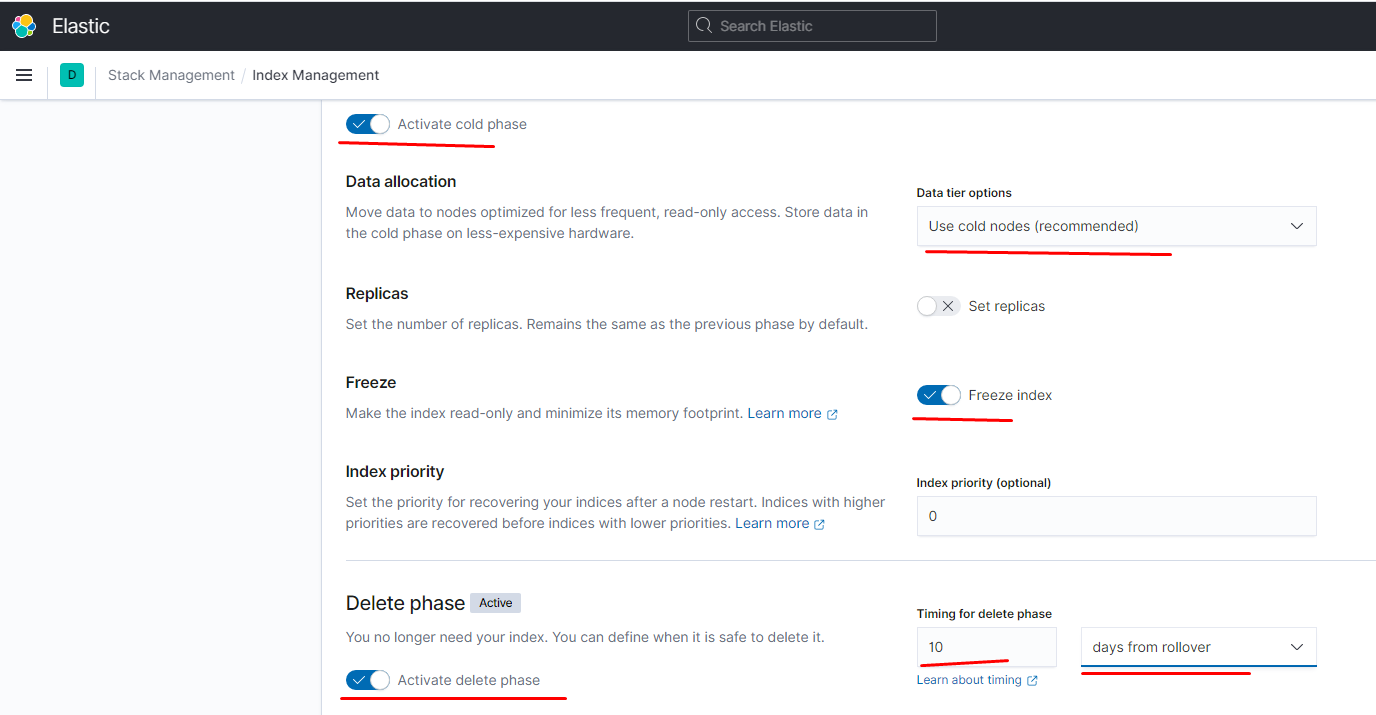
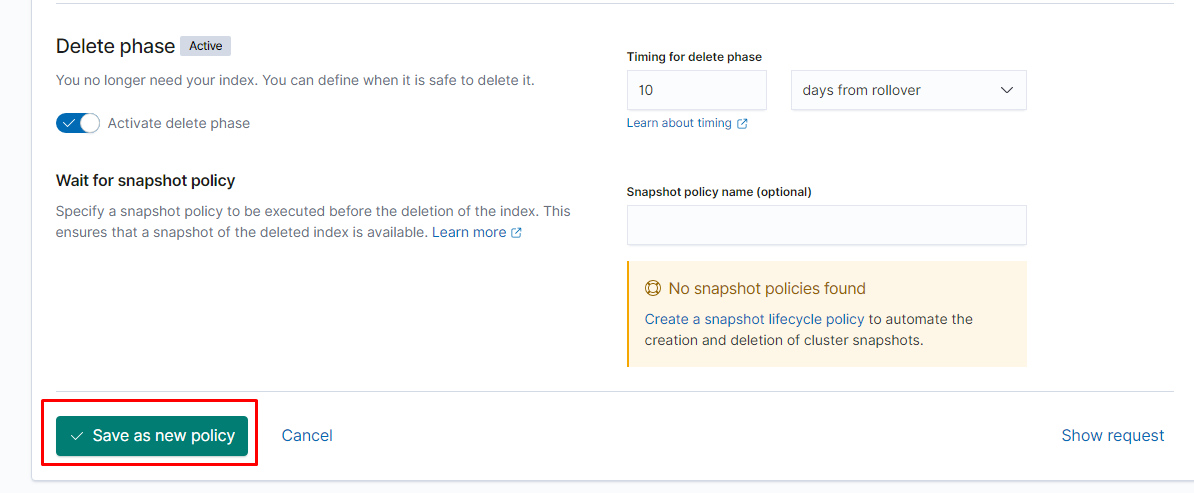
создаём шаблон:
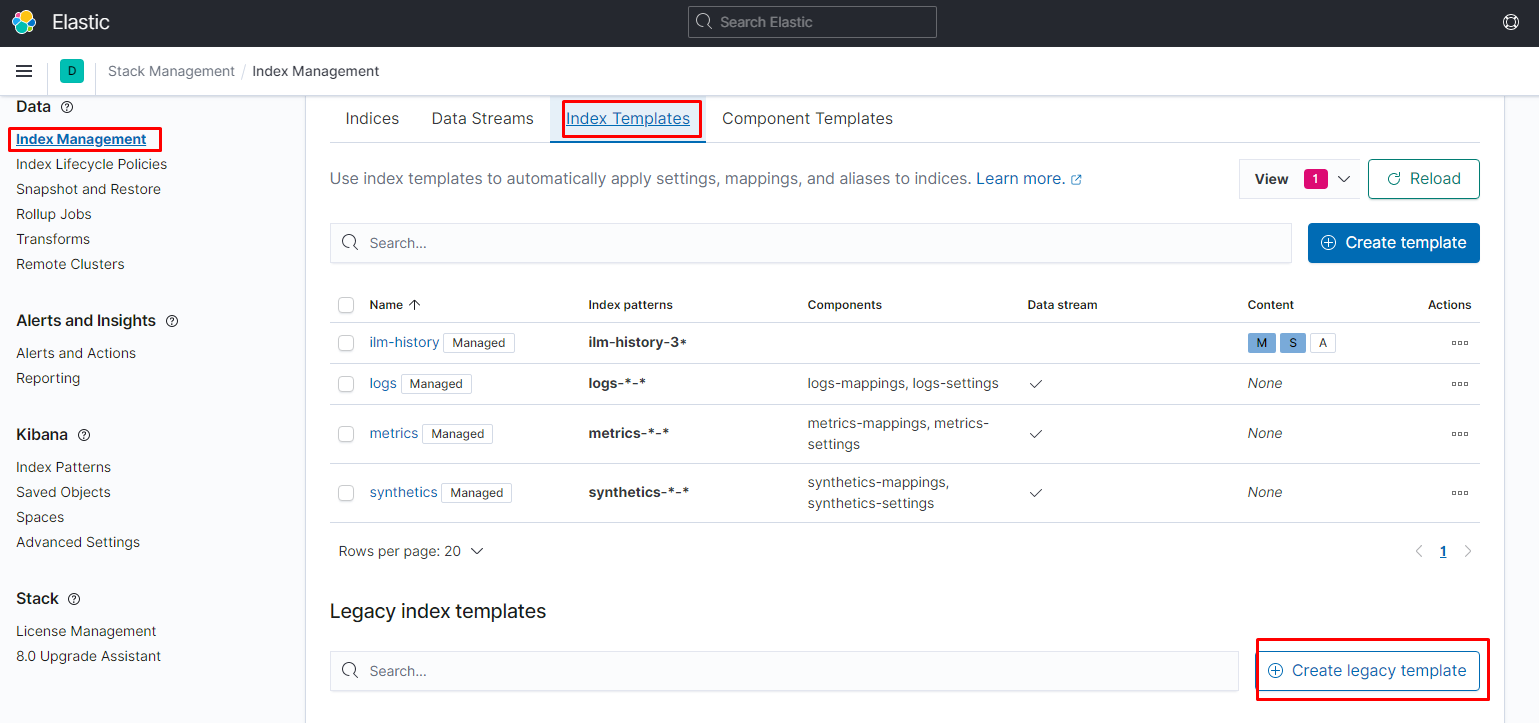
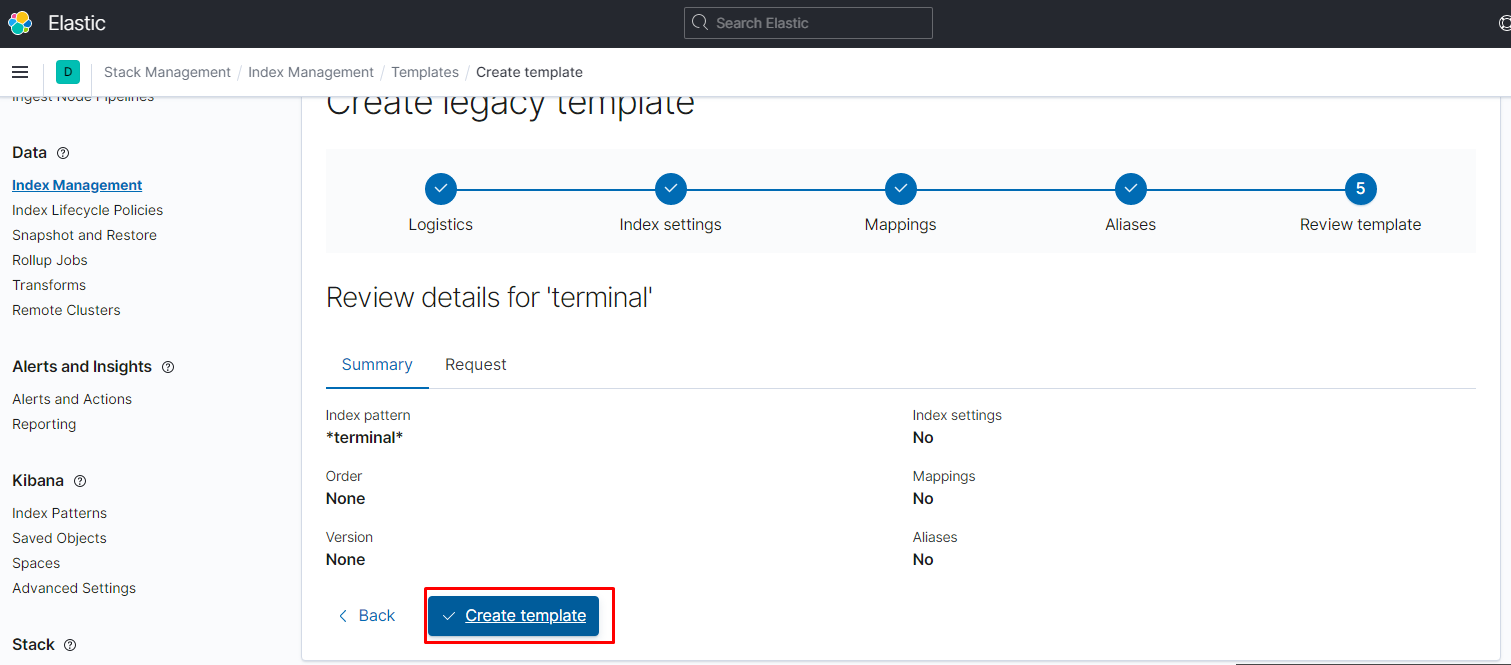
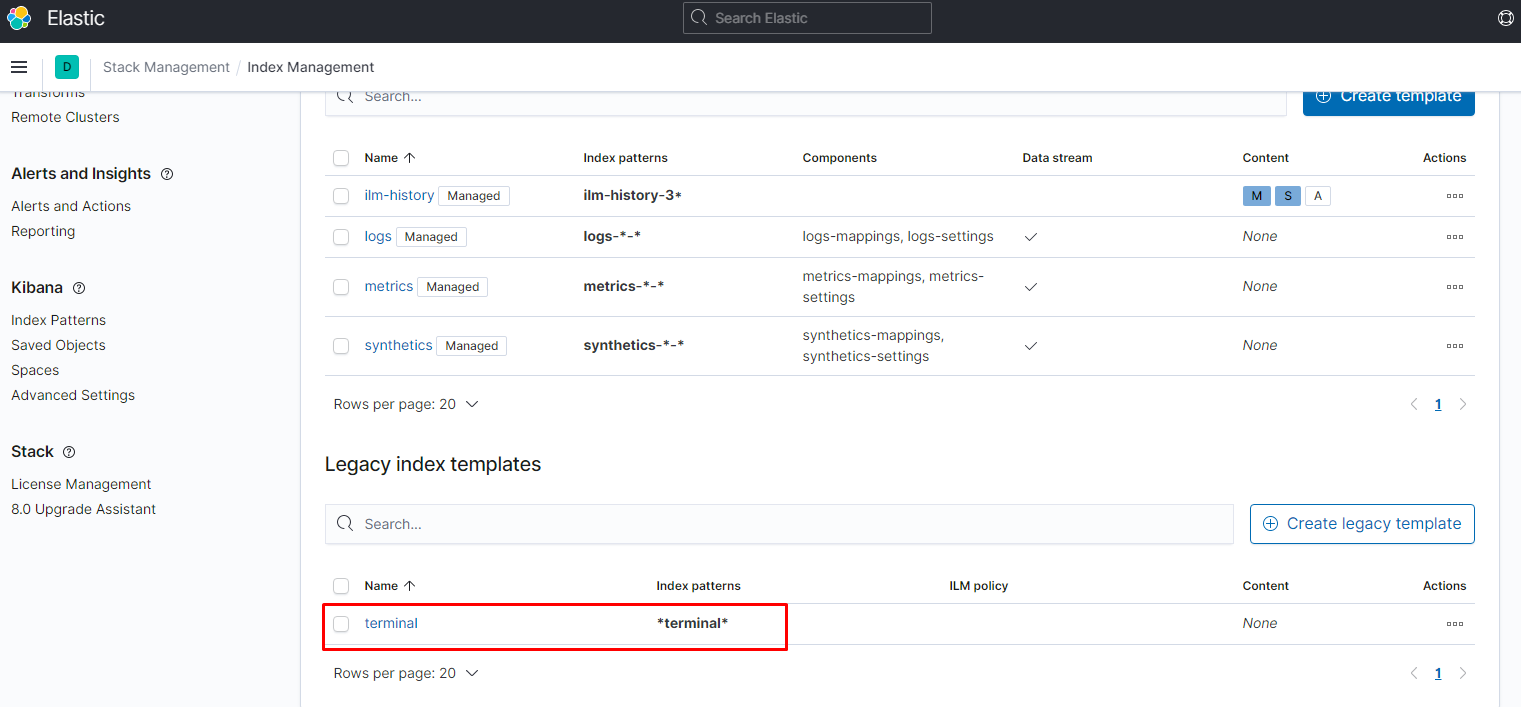
шаблон создан, цепляем на него политику
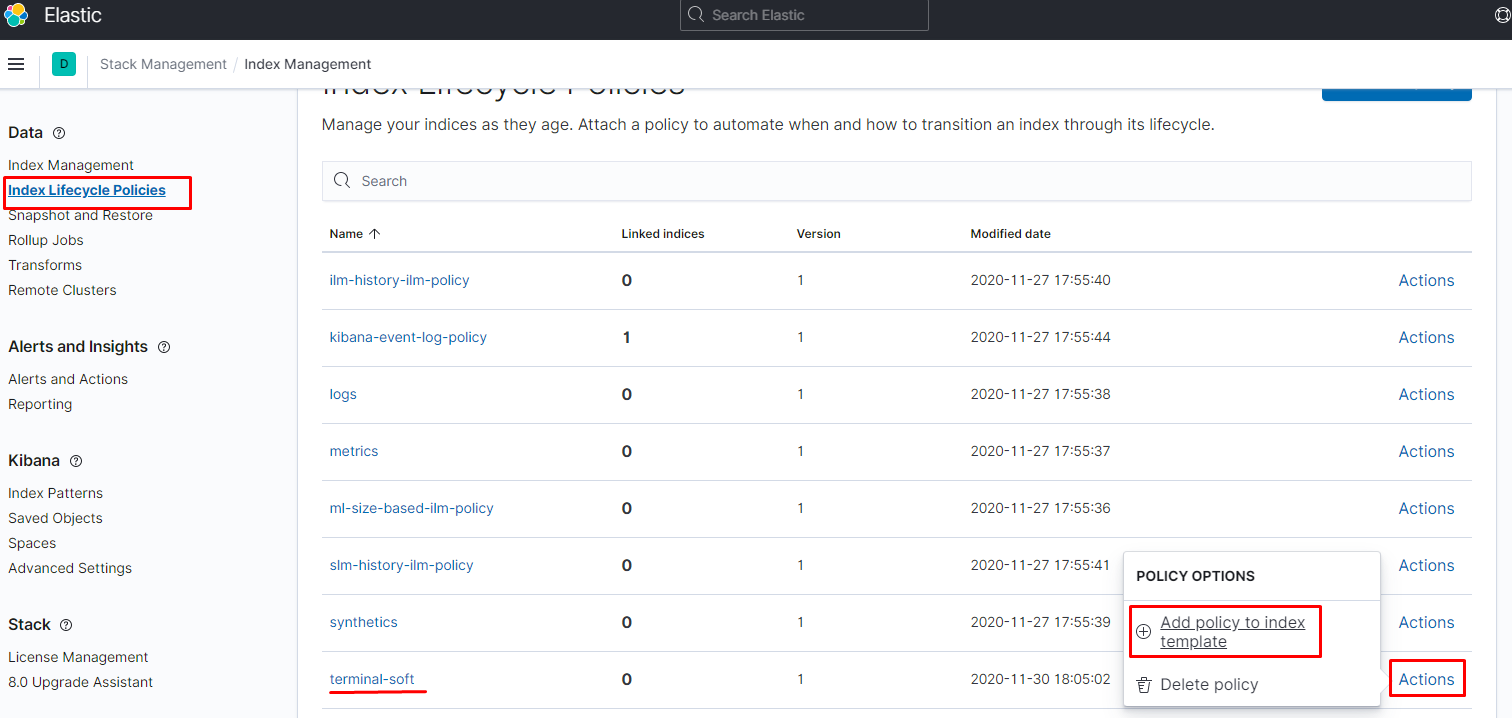
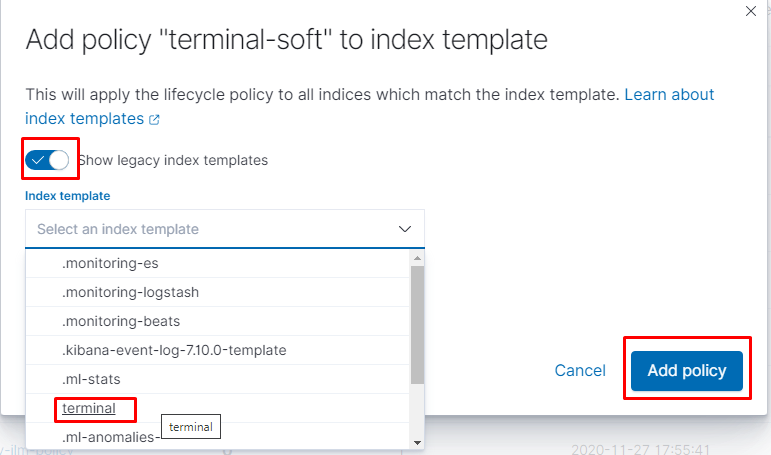
как видим всё нормально подцепилось:
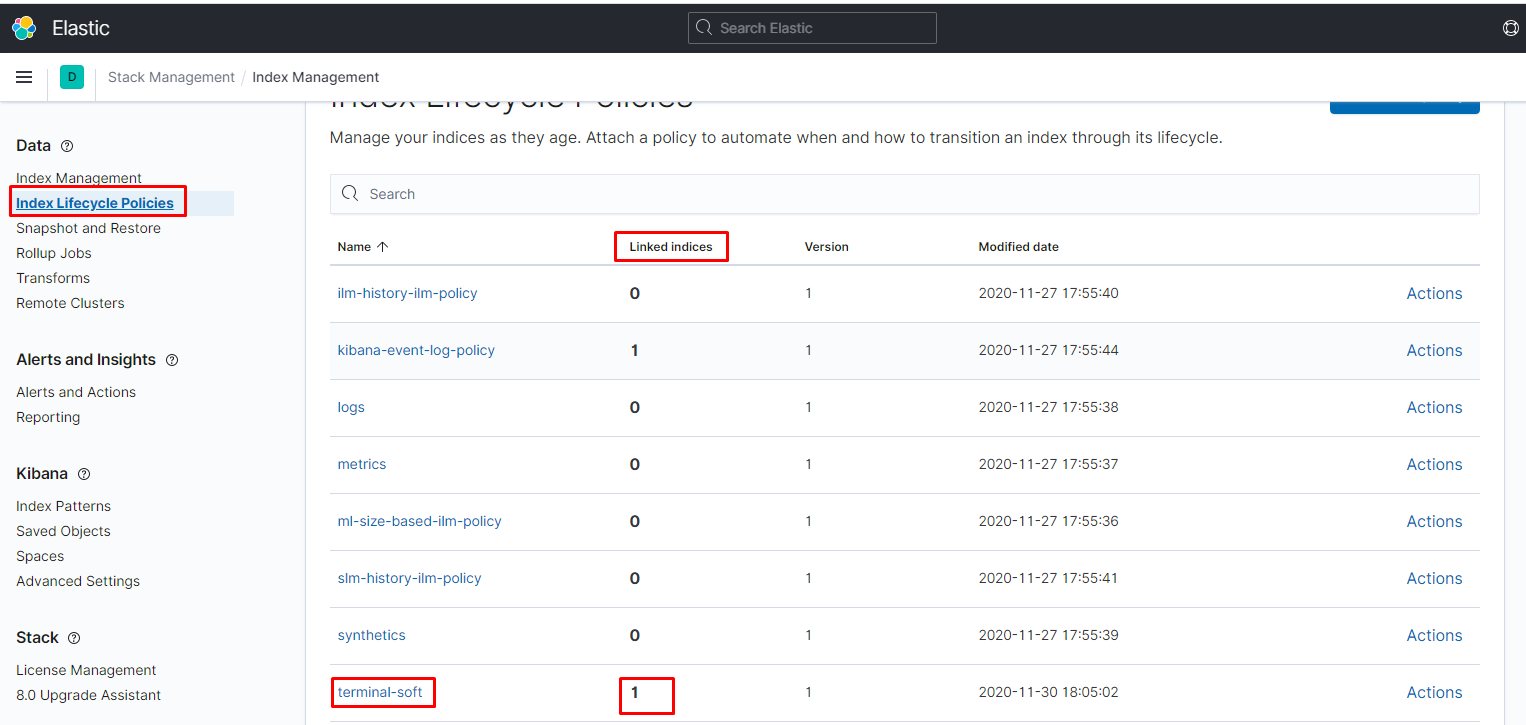
индексы создаются следующим образом, и ролловер нормально их не удаляет:
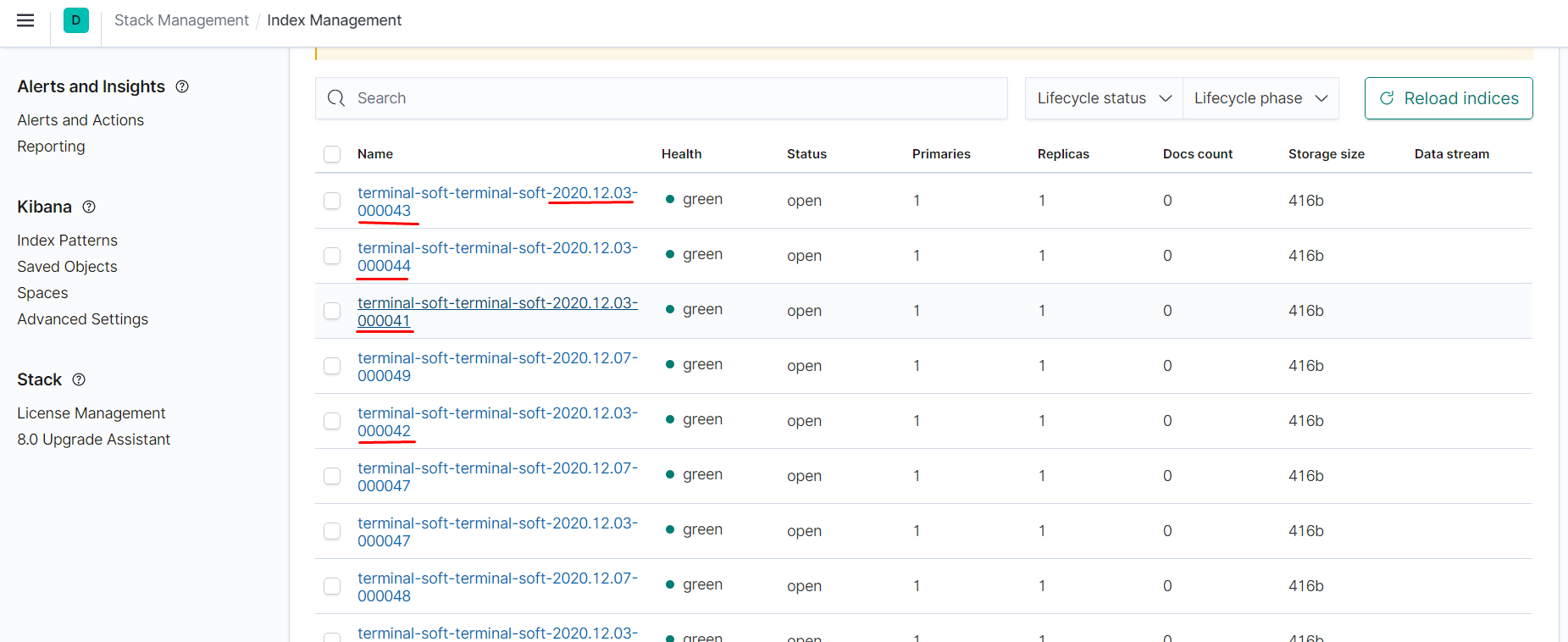
завести не удалось, поэтому хер знает что ему не нравится, поэтому 2 варианта либо прикручивать curator и нах ILM или ставим вместо efk - elk