Thank you for reading this post, don't forget to subscribe!
Роли узлов и демоны
Поверх операционной системы работают демоны Ceph, выполняющие различные роли кластера. Таким образом один сервер может выступать, например, и в роли монитора (MON), и в роли хранилища данных (OSD). А другой сервер тем временем может выступать в роли хранилища данных и в роли сервера метаданных (MDS). В больших кластерах демоны запускаются на отдельных машинах, но в малых кластерах, где количество серверов сильно ограничено, некоторые сервера могут выполнять сразу две или три роли. Зависит от мощности сервера и самих ролей. Разумеется, все будет работать шустрее на отдельных серверах, но не всегда это возможно реализовать. Кластер можно собрать даже из одной машины и всего одного диска, и он будет работать. Другой разговор, что это не будет иметь смысла. Следует отметить и то, что благодаря программной определяемости, хранилище можно поднять даже поверх RAID или iSCSI-устройства, однако в большинстве случаев это тоже не будет иметь смысла.
В документации перечислено 3 вида демонов:
- Mon — демон монитора
- OSD — демон хранилища
- MDS — сервер метаданных (необходим только в случае использования CephFS)
Первоначальный кластер можно создать из нескольких машин, совмещая на них роли кластера. Затем, с ростом кластера и добавлением новых серверов, какие-то роли можно дублировать на других машинах или полностью выносить на отдельные серверы.
Структура хранения
Кластер может иметь один или много пулов данных разного назначения и с разными настройками. Пулы делятся на плейсмент-группы. В плейсмент-группах хранятся объекты, к которым обращаются клиенты. На этом логический уровень заканчивается, и начинается физический, потому как за каждой плейсмент-группой закреплен один главный диск и несколько дисков-реплик (сколько именно зависит от фактора репликации пула). Другими словами, на логическом уровне объект хранится в конкретной плейсмент-группе, а на физическом — на дисках, которые за ней закреплены. При этом диски физически могут находиться на разных узлах или даже в разных датацентрах.
Фактор репликации (RF)
Фактор репликации — это уровень избыточности данных. Количество копий данных, которое будет храниться на разных дисках. За этот параметр отвечает переменная size. Фактор репликации может быть разным для каждого пула, и его можно менять на лету. Вообще, в Ceph практически все параметры можно менять на лету, мгновенно получая реакцию кластера. Сначала у нас может быть size=2, и в этом случае, пул будет хранить по две копии одного куска данных на разных дисках. Этот параметр пула можно поменять на size=3, и в этот же момент кластер начнет перераспределять данные, раскладывая еще одну копию уже имеющихся данных по дискам, не останавливая работу клиентов.
Пул
Пул — это логический абстрактный контейнер для организации хранения данных пользователя. Любые данные хранятся в пуле в виде объектов. Несколько пулов могут быть размазаны по одним и тем же дискам (а может и по разным, как настроить) с помощью разных наборов плейсмент-групп. Каждый пул имеет ряд настраиваемых параметров: фактор репликации, количество плейсмент-групп, минимальное количество живых реплик объекта, необходимое для работы и т. д. Каждому пулу можно настроить свою политику репликации (по городам, датацентрам, стойкам или даже дискам). Например, пул под хостинг может иметь фактор репликации size=3, а зоной отказа будут датацентры. И тогда Ceph будет гарантировать, что каждый кусочек данных имеет по одной копии в трех датацентрах. Тем временем, пул для виртуальных машин может иметь фактор репликации size=2, а уровнем отказа уже будет серверная стойка. И в этом случае, кластер будет хранить только две копии. При этом, если у нас две стойки с хранилищем виртуальных образов в одном датацентре, и две стойки в другом, система не будет обращать внимание на датацентры, и обе копии данных могут улететь в один датацентр, однако гарантированно в разные стойки, как мы и хотели.
Мониторы
Монитор — это демон, выполняющий роль координатора, с которого начинается кластер. Как только у нас появляется хотя бы один рабочий монитор, у нас появляется Ceph-кластер. Монитор хранит информацию о здоровье и состоянии кластера, обмениваясь различными картами с другими мониторами. Клиенты обращаются к мониторам, чтобы узнать, на какие OSD писать/читать данные. При разворачивании нового хранилища, первым делом создается монитор (или несколько). Кластер может прожить на одном мониторе, но рекомендуется делать 3 или 5 мониторов, во избежание падения всей системы по причине падения единственного монитора. Главное, чтобы их количество было нечетным, дабы избежать ситуаций раздвоения сознания (split-brain). Мониторы работают в кворуме, поэтому если упадет больше половины мониторов, кластер заблокируется для
OSD (Object Storage Device)
OSD — это юнит хранилища, который хранит сами данные и обрабатывает запросы клиентов, обмениваясь данными с другими OSD. Обычно это диск. И обычно за каждый OSD отвечает отдельный OSD-демон, который может запускаться на любой машине, на которой установлен этот диск. Это второе, что нужно добавлять в кластер, при разворачивании. Один монитор и один OSD — минимальный набор для того, чтобы поднять кластер и начать им пользоваться. Если на сервере крутится 12 дисков под хранилище, то на нем будет запущено столько же OSD-демонов. Клиенты работают непосредственно с самими OSD, минуя узкие места, и достигая, тем самым, распределения нагрузки. Клиент всегда записывает объект на первичный OSD для какой-то плейсмент группы, а уже дальше данный OSD синхронизирует данные с остальными (вторичными) OSD из этой же плейсмент-группы. Подтверждение успешной записи может отправляться клиенту сразу же после записи на первичный OSD, а может после достижения минимального количества записей (параметр пула min_size). Например если фактор репликации size=3, а min_size=2, то подтверждение об успешной записи отправится клиенту, когда объект запишется хотя бы на два OSD из трех (включая первичный).
При разных вариантах настройки этих параметров, мы будем наблюдать и разное поведение.
Если size=3 и min_size=2: все будет хорошо, пока 2 из 3 OSD плейсмент-группы живы. Когда останется всего лишь 1 живой OSD, кластер заморозит операции данной плейсмент-группы, пока не оживет хотя бы еще один OSD.
Если size=min_size, то плейсмент-группа будет блокироваться при падении любого OSD, входящего в ее состав. А из-за высокого уровня размазанности данных, большинство падений хотя бы одного OSD будет заканчиваться заморозкой всего или почти всего кластера. Поэтому параметр size всегда должен быть хотя бы на один пункт больше параметра min_size.
Если size=1, кластер будет работать, но смерть любой OSD будет означать безвозвратную потерю данных. Ceph дозволяет выставить этот параметр в единицу, но даже если администратор делает это с определенной целью на короткое время, он риск берет на себя.
Диск OSD состоит из двух частей: журнал и сами данные. Соответственно, данные сначала пишутся в журнал, затем уже в раздел данных. С одной стороны это дает дополнительную надежность и некоторую оптимизацию, а с другой стороны — дополнительную операцию, которая сказывается на производительности. Вопрос производительности журналов рассмотрим ниже.
Плейсмент-группа (PG)
Плейсмент-группы — это такое связующее звено между физическим уровнем хранения (диски) и логической организацией данных (пулы).
Каждый объект на логическом уровне хранится в конкретной плейсмент-группе. На физическом же уровне, он лежит в нужном количестве копий на разных физических дисках, которые в эту плейсмент-группу включены (на самом деле не диски, а OSD, но обычно один OSD это и есть один диск, и для простоты я буду называть это диском, хотя напомню, за ним может быть и RAID-массив или iSCSI-устройство). При факторе репликации size=3, каждая плейсмент группа включает в себя три диска. Но при этом каждый диск находится во множестве плейсмент-групп, и для каких то групп он будет первичным, для других — репликой. Если OSD входит, например, в состав трех плейсмент-групп, то при падении такого OSD, плейсмент-группы исключат его из работы, и на его место каждая плейсмент-группа выберет рабочий OSD и размажет по нему данные. С помощью данного механизма и достигается достаточно равномерное распределение данных и нагрузки. Это весьма простое и одновременно гибкое решение.
Алгоритм CRUSH
В основе механизма децентрализации и распределения лежит так называемый CRUSH-алгоритм (Controlled Replicated Under Scalable Hashing), играющий важную роль в архитектуре системы. Этот алгоритм позволяет однозначно определить местоположение объекта на основе хеша имени объекта и определенной карты, которая формируется исходя из физической и логической структур кластера (датацентры, залы, ряды, стойки, узлы, диски). Карта не включает в себя информацию о местонахождении данных. Путь к данным каждый клиент определяет сам, с помощью CRUSH-алгоритма и актуальной карты, которую он предварительно спрашивает у монитора. При добавлении диска или падении сервера, карта обновляется.
Благодаря детерминированности, два разных клиента найдут один и тот же однозначный путь до одного объекта самостоятельно, избавляя систему от необходимости держать все эти пути на каких-то серверах, синхронизируя их между собой, давая огромную избыточную нагрузку на хранилище в целом.
Кеширование
Ceph предусматривает несколько способов увеличения производительности кластера методами кеширования.
Primary-Affinity
У каждого OSD есть несколько весов, и один из них отвечает за то, какой OSD в плейсмент-группе будет первичным. А, как мы выяснили ранее, клиент пишет данные именно на первичный OSD. Так вот, можно добавить в кластер пачку SSD дисков, сделав их всегда первичными, снизив вес primary-affinity HDD дисков до нуля. И тогда запись будет осуществляться всегда сначала на быстрый диск, а затем уже не спеша реплицироваться на медленные. Этот метод самый неправильный, однако самый простой в реализации. Главный недостаток в том, что одна копия данных всегда будет лежать на SSD и потребуется очень много таких дисков, чтобы полностью покрыть репликацию. Хотя этот способ кто-то и применял на практике, но его я скорее упомянул для того, чтобы рассказать о возможности управления приоритетом записи.
Вынос журналов на SSD
Вообще, львиная доля производительности зависит от журналов OSD. Осуществляя запись, демон сначала пишет данные в журнал, а затем в само хранилище. Это верно всегда, кроме случаев использования BTRFS в качестве файловой системы на OSD, которая может делать это параллельно благодаря технике copy-on-write, но я так и не понял, насколько она готова к промышленному применению. На каждый OSD идет собственный журнал, и по умолчанию он находится на том же диске, что и сами данные. Однако, журналы с четырёх или пяти дисков можно вынести на один SSD, неплохо ускорив операции записи. Метод не очень гибкий и удобный, но достаточно простой. Недостаток метода в том, что при вылете SSD с журналом, мы потеряем сразу несколько OSD, что не очень приятно и вносит дополнительные трудности во всю дальнейшую поддержку, которая скалируется с ростом кластера.
Кеш-тиринг
Ортодоксальность данного метода в его гибкости и масштабируемости. Схема такова, что у нас есть пул с холодными данными и пул с горячими. При частом обращении к объекту, тот как бы нагревается и попадает в горячий пул, который состоит из быстрых SSD. Затем, если объект остывает, он попадает в холодный пул с медленными HDD. Данная схема позволяет легко менять SSD в горячем пуле, который в свою очередь может быть любого размера, ибо параметры нагрева и охлаждения регулируются.
С точки зрения клиента
Ceph предоставляет для клиента различные варианты доступа к данным: блочное устройство, файловая система или объектное хранилище.
Блочное устройство (RBD, Rados Block Device)
Ceph позволяет в пуле данных создать блочное устройство RBD, и в дальнейшем смонтировать его на операционных системах, которые это поддерживают (на момент написания статьи были только различные дистрибутивы linux, однако FreeBSD и VMWare тоже работают в эту сторону). Если клиент не поддерживает RBD (например Windows), то можно использовать промежуточный iSCSI-target с поддержкой RBD (например, tgt-rbd). Кроме того, такое блочное устройство поддерживает снапшоты.
Файловая система CephFS
Клиент может смонтировать файловую систему CephFS, если у него linux с версией ядра 2.6.34 или новее. Если версия ядра старше, то можно смонтировать ее через FUSE (Filesystem in User Space). Для того, чтобы клиенты могли подключать Ceph как файловую систему, необходимо в кластере поднять хотя бы один сервер метаданных (MDS)
Шлюз объектов
С помощью шлюза RGW (RADOS Gateway) можно клиентам дать возможность пользоваться хранилищем через RESTful Amazon S3 или OpenStack Swift совместимое API.
Более подробно:
Мониторы Ceph (Ceph Monitors) поддерживают главную копию (master copy) кластерной карты (cluster map), по которой клиенты Ceph могут определить расположение всех мониторов, OSD демонов и серверов Metadata (MDS). До того как клиенты начнут что-либо писать или читать у OSD или MDS, они должны в первую очередь связаться с монитором Ceph.
С текущей кластерной картой и алгоритмом CRUSH, клиенты могут вычислить расположение любого объекта. Эта способность позволяет клиентам напрямую общаться с OSD, что является важным аспектом в архитектуре Ceph и его способности к высокой доступности и производительности.
Главная задача мониторов - поддерживать главную копию кластерной карты. Помимо этого мониторы занимаются аутентификацией и журналированием. Кластерная карта - это комплексная карта. Она состоит из карты мониторов (monitor map), карты OSD (OSD map), карты плейсмент-группы (placement group map) и карты MDS (metadata server map).
В кластере может быть один монитор, но он сразу станет единой точкой отказа (single-point-of-failure). Для обеспечения высокой доступности нужно запускать множество мониторов на различных нодах. Необязательно, но желательно, чтобы количество мониторов в вашем кластере было нечётным числом для улучшения работы алгоритма Paxos при сохранении кворума. В идеале, разработчики Ceph советуют ноды-мониторы не совмещать с нодами OSD, так как мониторы активно используют fsync() и это пагубно влияет на производительность OSD.
Следует знать об архитектурной особенности мониторов. Ceph накладывает жёсткие требования согласования для монитора, когда тот разыскивает другие мониторы в кластере. Другие демоны Ceph и клиенты используют конфигурационный файл для обнаружения мониторов, сами мониторы используют для этого карту мониторов (monmap), а не конфигурационный файл. Использование monmap вместо конфигурационного файла Ceph позволяет избежать ошибок, которые могут привести к разрушению кластера (например, в результате опечатки в ceph.conf при указании адреса монитора или порта). Тем более, что конфигурационный файл Ceph обновляется и распространяется человеком, а не автоматически, и мониторы могли бы не преднамеренно использовать старую версию конфигурации.
OSD (object storage daemon) — в каждой ноде кластера может быть несколько дисков и на каждый диск нужен отдельный демон OSD.
В традиционной архитектуре клиент общается с неким центральным компонентом (шлюз, брокер, API и так далее), который сразу становится единой точкой отказа этой сложной системы. Так же обычно центральный элемент является бутылочным горлышком в плане производительности. Ceph избавляется от центрального элемента в своей структуре, позволяя клиентам общаться с OSD демонами напрямую с помощью алгоритма CRUSH.
Демоны Ceph OSD сохраняют данные в виде объектов в плоском пространстве имён, то есть без иерархии в виде каталогов. Объекты обладают идентификаторами, бинарными данными и метаданными в виде ключ-значение, которые использует MDS сохраняя владельца файла, время создания, время модификации и так далее. Идентификатор объекта уникален в пределах кластера.
Демон OSD в составе кластера постоянно сообщает о своём статусе - up или down. Если по ряду причин OSD демон не сообщает о своём состоянии, демон монитора периодически сам проверяет статус OSD демонов и уполномочен обновлять кластерную карту и уведомлять других демонов мониторов о состоянии OSD демонов.
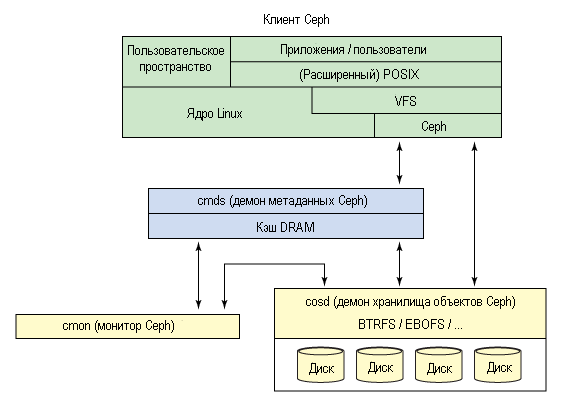
Metadata server (MDS) — вспомогательный демон для обеспечения синхронного состояния файлов в точках монтирования CephFS. В один момент времени работает только один MDS в пределах кластера, а другие находятся в режиме ожидания и кто-то станет активным, если текущий MDS упадёт.