Thank you for reading this post, don't forget to subscribe!
AWS отключил нам отправку писем через AWS SES из-за bounce-рейта.
Проверить это можно в AWS SES > Reputation Dashboard, аккаунт сейчас в статусе Under review:
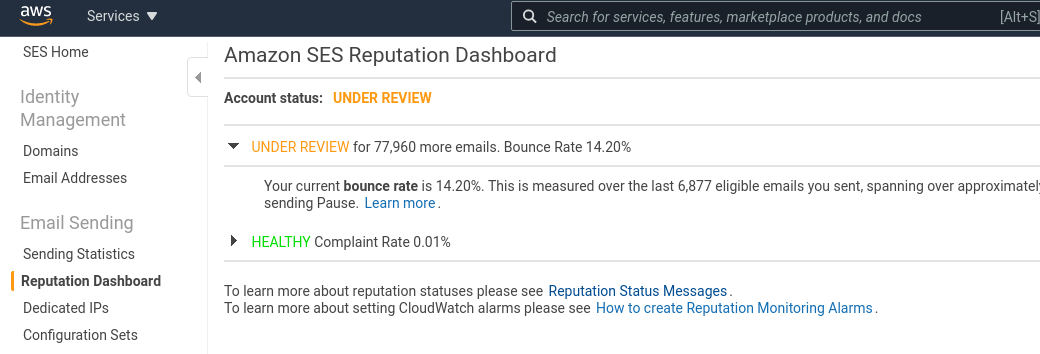
После обращения в тех. поддержку отправку почты нам временно включили, но решить проблему надо, а заодно – следить, что бы подобное не случалось в будущем.
Bounce и Complaint rate
Запретить отправку почты AWS может по двум причинам – завышенный Bounce rate и завышенный Complaint rate. В случае высокого рейтинга – почтовые сервера могут помечать сервер отправки как “спамера”, и блокировать приходящие с него письма вообще, что, разумеется, негативно сказывается на AWS SES, а потому они достаточно активно следят за этими показателями и могут (и отключают) отправку с этого SES-аккаунта.
Кратко рассмотрим, что такое Bounce и Compliant рейтинги, а потом настроим мониторинг с CloudWatch и Prometheus, что бы в Slack получать уведомления о превышении пороговых значений – 5% bounce, и свыше 1% compliant rates.
Общие советы по уменьшению Bounce rate можно найти в What can I do to minimize bounces?
Bounce rate
Bounce rate определяет, какая часть получателей не получила отправленного письма, см. Bounce Rate.
Считается как (кол-во bounced / кол-во отправленных всего) * 100, например:
|
1 2 |
>>> (10.0/10000)*100 0.1 |
Тут получаем 0.1% – отличный результат, если бы был реальным
Hard and Soft Bounce
При этом различают два типа bounce – hard и soft.
- Hard bounce: при “жёстком” отказе – сервер получателя отказывается принимать письмо вообще. Обычно это возникает из-за ошибок типа отсутствия ящика получателя на сервере, домена, в который отправляется письмо, или если сервер вообще отказывается получать какие-либо письма
- Soft bounce: сюда входят письма, которые сервер получателя принял и передал в пользовательский почтовый ящик, но не смог его доставить туда из-за, например, превышения ящиком дисковой квоты или размера письма
Complaint rate
Complaint rate считается, когда пользователь явно уведомляет, что он не хочет получать письма, например через кнопку “Report spam” в своём почтовом клиенте, или отправив жалобу напрямую AWS SES.
AWS SES CloudWatch metrics
Для алертинга используем метрики CloudWatch для AWS SES:
- Sends: общее количество отправленных писем
- Deliveries: общее количество доставленных писем
- Bounces: сервер получателя отказался доставлять письмо в ящик (считаются hard bounces)
- Complaints: письмо было доставлено получателю, но он отметил его как спам
Плюс дополнительно уже посчитаны значения для Bounce и Complaint – Reputation.BounceRate и Reputation.ComplaintRate.
Сейчас наше значение для Reputation.BounceRate == 0.1432, т.е. 14%:
(в конце этого поста рейтинг будет уже 18% – за сутки набрали ещё 4%)
Можно создать алерты используя сам AWS CloudWatch Alerts и SNS, см. Creating reputation monitoring alarms using CloudWatch, либо собирать метрики во внешнюю систему мониторинга, и слать алерты через неё.
В нашем случае, будем собирать в Prometheus, который через свой Alertmanager будет слать алерты в Opsgenie, а из него уже – нам в Slack.
Настройка Prometheus CloudWatch Exporter
мы используем yet-another-cloudwatch-exporter, но в случае с метриками для AWS SES он выводил полную ерунду, в Guthub Issues на вопросы отвечают редко, да и вообще он производит впечатление заброшенного проекта, хотя апдейты периодически выкатывают.
Поэтому для SES отдельно используем стандартный експортер, Prometheus: CloudWatch exporter — сбор метрик из AWS и графики в Grafana.
Его конфиг:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
region: us-east-1 set_timestamp: false delay_seconds: 60 metrics: - aws_namespace: AWS/SES aws_metric_name: Send - aws_namespace: AWS/SES aws_metric_name: Delivery - aws_namespace: AWS/SES aws_metric_name: Bounce - aws_namespace: AWS/SES aws_metric_name: Complaint - aws_namespace: AWS/SES aws_metric_name: Reputation.BounceRate - aws_namespace: AWS/SES aws_metric_name: Reputation.ComplaintRate |
Для проверки метрик можно запустить скрипт
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
#!/usr/bin/env python import sys import smtplib import email.utils from email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText def makeemail(from_name, from_user, to_user): # The subject line of the email. subject = 'Amazon SES Test (Python smtplib)' # The email body for recipients with non-HTML email clients. body_text = ("Amazon SES Test\r\n" "This email was sent through the Amazon SES SMTP " "Interface using the Python smtplib package." ) # The HTML body of the email. body_html = """<html> <head></head> <body> <h1>Amazon SES SMTP Email Test</h1> <p>This email was sent with Amazon SES using the <a href='https://www.python.org/'>Python</a> <a href='https://docs.python.org/3/library/smtplib.html'> smtplib</a> library.</p> </body> </html> """ # Create message container - the correct MIME type is multipart/alternative. msg = MIMEMultipart('alternative') msg['Subject'] = subject msg['From'] = email.utils.formataddr((from_name, from_user)) msg['To'] = to_user # Record the MIME types of both parts - text/plain and text/html. part1 = MIMEText(body_text, 'plain') part2 = MIMEText(body_html, 'html') # Attach parts into message container. # According to RFC 2046, the last part of a multipart message, in this case # the HTML message, is best and preferred. msg.attach(part1) msg.attach(part2) return msg def send_email(host, port, smtp_user, smtp_pass, from_user, to_user, message): # Try to send the message. try: server = smtplib.SMTP(host, port) server.ehlo() server.starttls() server.ehlo() server.login(smtp_user, smtp_pass) server.sendmail(from_user, to_user, message.as_string()) server.close() except Exception as e: print ("Error: ", e) else: print ("Email sent!") if __name__ == "__main__": # Replace smtp_username with your Amazon SES SMTP user name. smtp_user = sys.argv[1] # Replace smtp_password with your Amazon SES SMTP password. smtp_pass = sys.argv[2] # If you're using Amazon SES in an AWS Region other than US West (Oregon), # replace email-smtp.us-west-2.amazonaws.com with the Amazon SES SMTP # endpoint in the appropriate region. host = "email-smtp.eu-west-1.amazonaws.com" port = 587 # Replace sender@example.com with your "From" address. # This address must be verified. from_user = 'noreply@setevoy.org.ua' from_name = 'Arseny' # Replace recipient@example.com with a "To" address. If your account # is still in the sandbox, this address must be verified. to_user = 'noreply@setevoy.org.ua' message = makeemail(from_name, from_user, to_user) send_email(host, port, smtp_user, smtp_pass, from_user, to_user, message) |
который раз в 10 секунд отправляет письмо:
watch -n 10 ./ses_email.py
Добавим графики в Grafana:
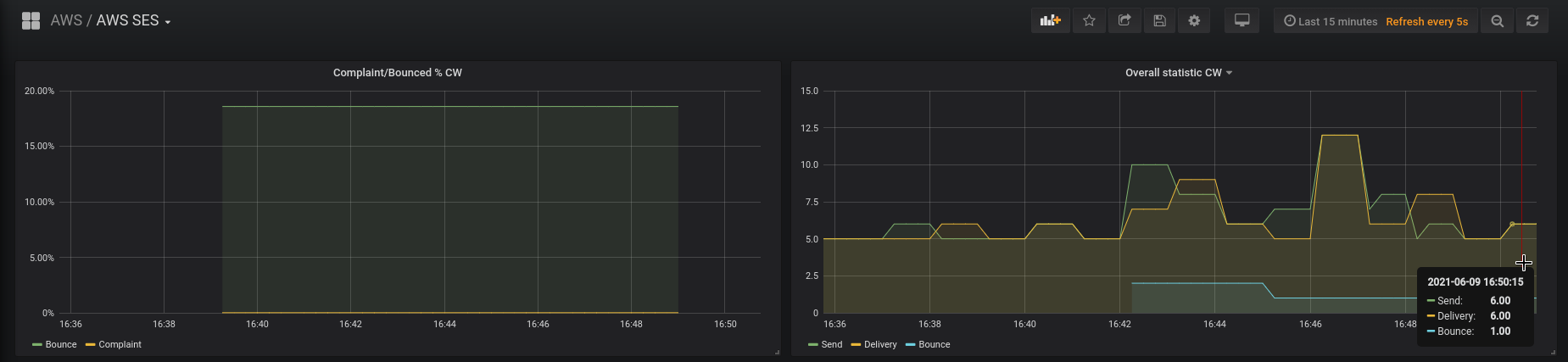
Сравним их с метриками в самом CloudWatch, что бы убедиться, что всё считается верно:
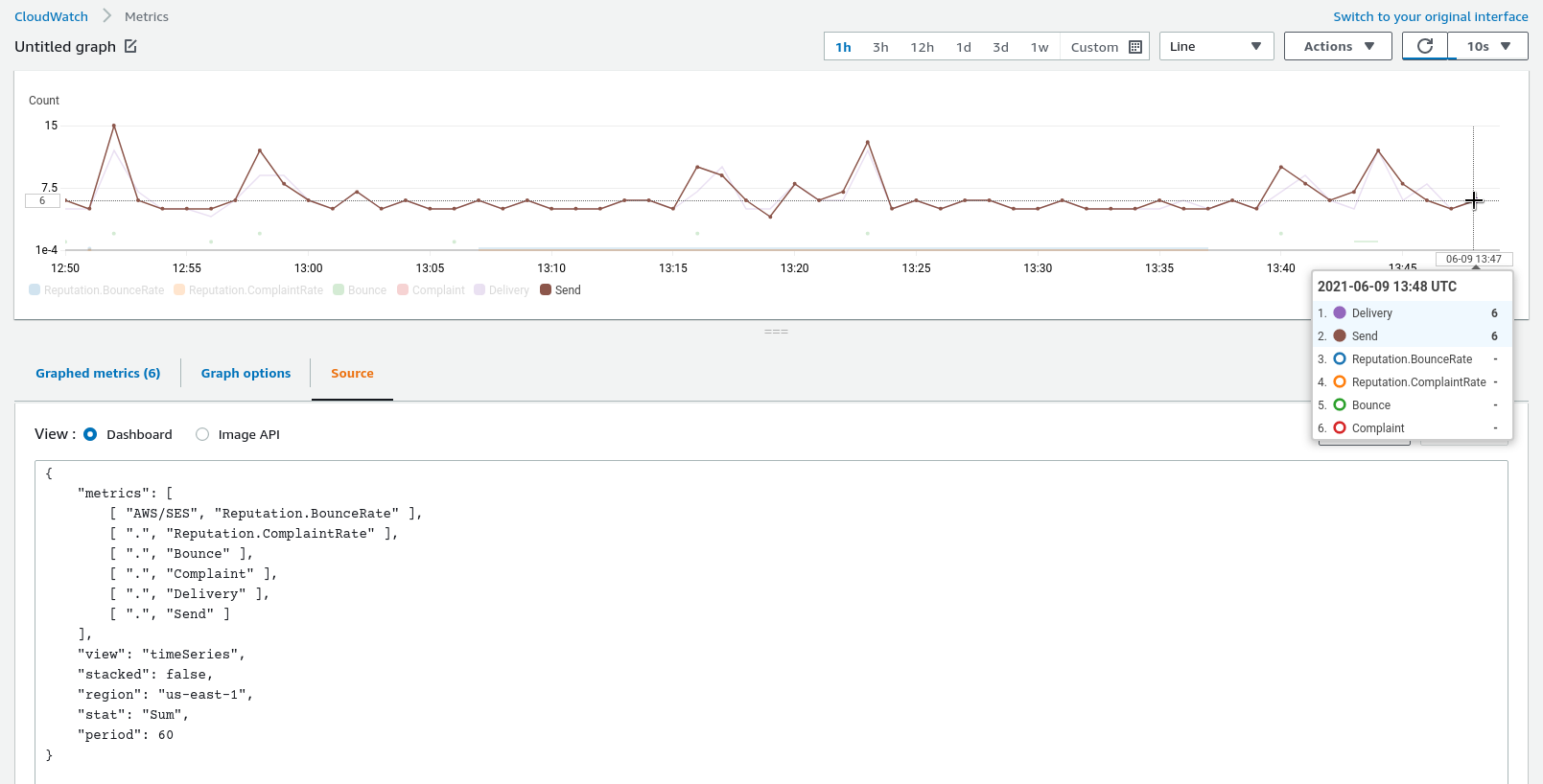
И осталось добавить алерт.
Prometheus alert
Но тут возникает проблема.
Из графика видно, что Bounce Rate выводится неравномерно:
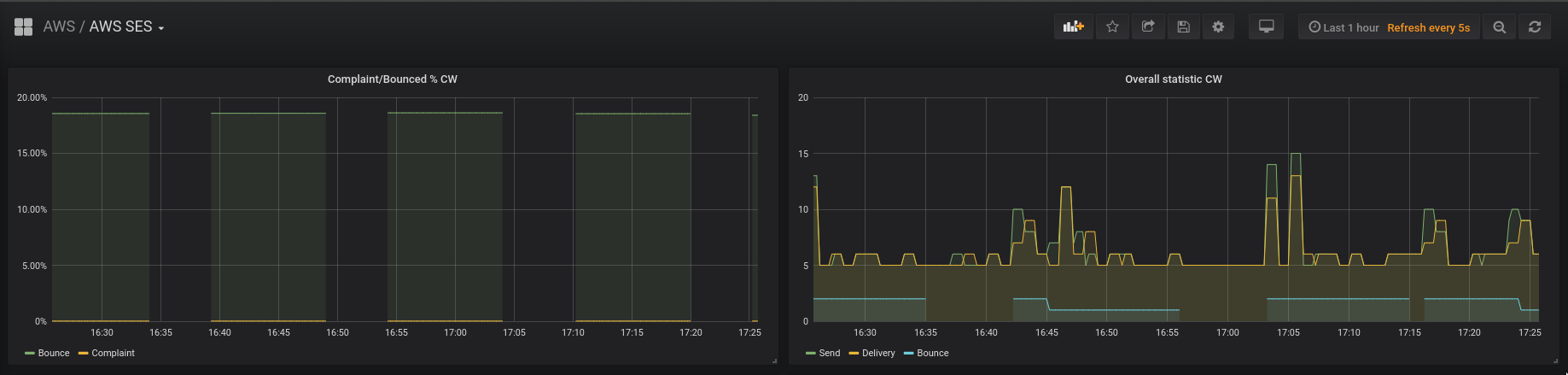
Примерно раз в 20 минут запускается наша рассылка (5-6 отправок в минуту на графике – это тестовые, создаваемые запущенным выше скриптом), и сразу же появляются значения для метрики aws_ses_reputation_bounce_rate_sum.
Если использовать самый простой алерт типа:
|
1 2 3 4 5 6 7 8 9 |
- alert: AWSSESReputationBounceRate expr: aws_ses_reputation_bounce_rate_sum{job="aws_ses"} * 100 > 5 for: 1s labels: severity: warning annotations: summary: 'AWS SES Bounce rate too high' description: 'Latest observed value: {{ $value | humanize }} %' tags: aws |
То он будет активироваться и закрываться раз в те же 20 минут.
Что можно сделать?
Как вариант – использовать avg_over_time(), и делать выборку по данным за последние, например, 10 минут – тогда получим ровный график:
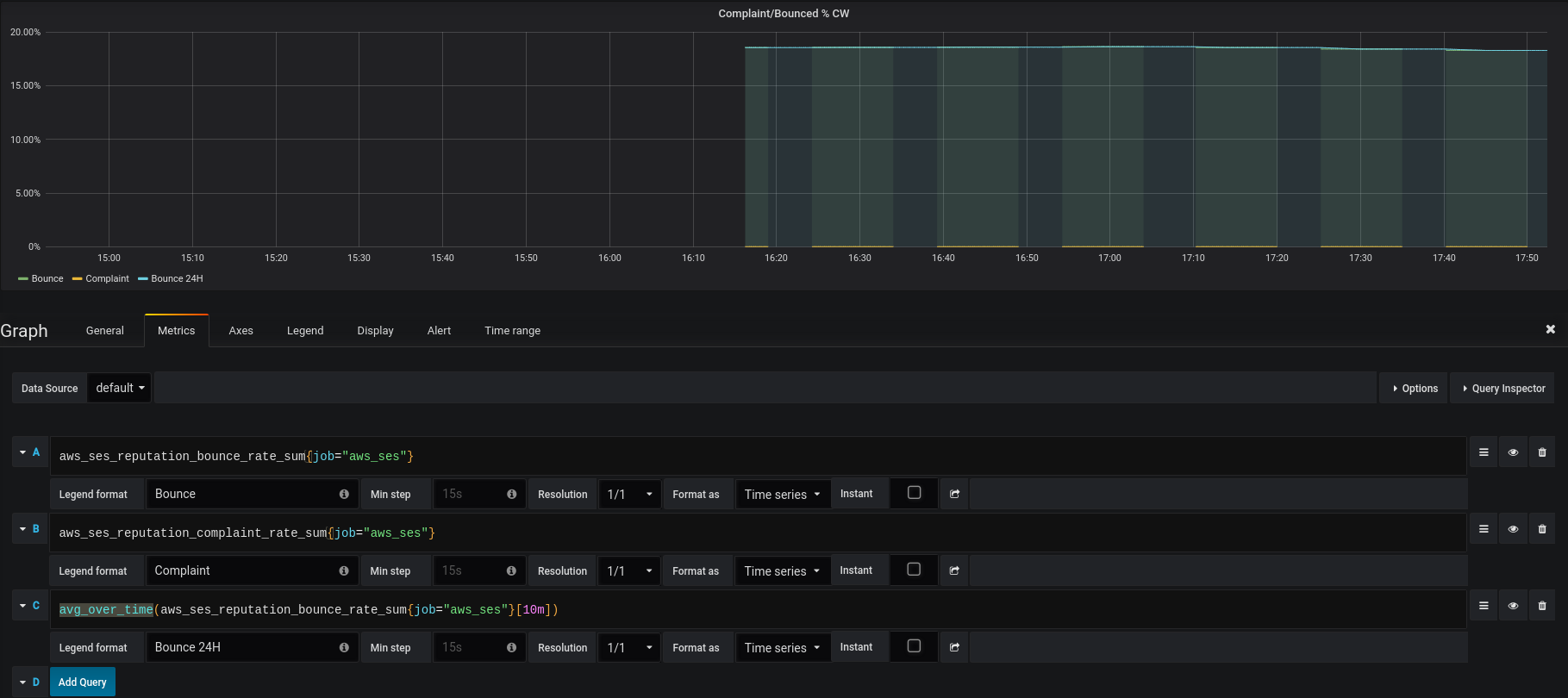
Обновляем алерт (тут задал 1 час):
|
1 2 3 4 5 6 7 8 9 |
- alert: AWSSESReputationBounceRate expr: avg_over_time(aws_ses_reputation_bounce_rate_sum{job="aws_ses"}[1h]) * 100 > 5 for: 1s labels: severity: warning annotations: summary: 'AWS SES Bounce rate too high' description: 'Latest observed value: {{ $value | humanize }} %' tags: aws |
И получаем алерт в Slack:

готово