Thank you for reading this post, don't forget to subscribe!
Инструментов для работы с логами навалом, но мы посмотрим в сторону ELK стека от Elastic. А именно: Elasticsearch, Logstash и Kibana — хранилище/поисковик, обработчик данных и тулза для их визуализации. А начнём, естественно, с первой буквы этого трёх-буквенного алфавита — «E».
Что такое Elasticsearch
Elasticsearch — это быстрый, горизонтально масштабируемый и очень бесплатный гибрид NoSQL базы данных и гугла для неё. С миром он общается через HTTP API и через него уже получает на вход JSON документы для индексации и хранения. Хранение, правда, можно отключить, и тогда останется только поисковик, возвращающий айдишки когда-то проиндексированных документов.
Установка
Так как Elasticsearch написан на Java, устанавливается он очень просто: качаем архив, распаковываем и запускаем bin/elasticsearch. Правда, запустить его через Docker будет еще проще: docker run -d -p9200:9200 elasticsearch. Всё общение будет проходить через порт 9200, так что самое время в него постучаться.
Осматриваемся
Вэбинары и официальная документация обычно показывают демки, используя еще один продукт от Elastic — Kibana. Но так речь идёт об обычном HTTP и JSON, отправлять и получать запросы можно чем угодно. Наверное, самый простой готовый инструмент — консоль и curl.
Итак, у нас есть порт 9200. Попробуем его пнуть просто так:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
$ curl 127.0.0.1:9200
#{
# "name" : "e-wGdWV",
# "cluster_name" : "elasticsearch",
# "cluster_uuid" : "ZxPcxDlFTSu68zpY9foYiw",
# "version" : {
# "number" : "5.2.0",
# "build_hash" : "24e05b9",
# "build_date" : "2017-01-24T19:52:35.800Z",
# "build_snapshot" : false,
# "lucene_version" : "6.4.0"
# },
# "tagline" : "You Know, for Search"
#}
|
Неплохо. Номер версии в середине ответа и шутка юмора внизу — запрос определенно того стоил.
Есть и другие полезные запросы, для которых в индексе не обязательно должны быть данные. Например, можно проверить статус узла:
|
1
2
3
|
$ curl 127.0.0.1:9200/_cat/health?v
#epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
#1486360312 05:51:52 elasticsearch yellow 1 1 5 5 0 0 5 0 - 50.0%
|
Или получить список индексов:
|
1
2
|
$ curl 127.00.1:9200/_cat/indices?v
#health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
|
Так как установка свежая, то, разумеется, индексов в ней никаких еще нет. Но мы как-то внезапно начали оперировать специфическими терминами, вроде узла и индекса, так что стоит сначала разобраться с терминологией.
Терминология Elasticsearch
Итак, мы уже упомянули узел (node), что на самом деле означает отдельно взятый процесс elasticsearch с его данными и настройками. Даже один узел образует кластер. Но если узлов в кластере несколько, то включённый по умолчанию шардинг (дробление) индексов и репликация шардов (shards) резко повысит и выживаемость индексов за счёт избыточности, и скорость запросов к ним за счёт параллелизации. Похожий подход, кстати, работает и в Kafka, только там шарды называются разделами.
Сам по себе индекс — это просто коллекция документов. В пределах кластера их может быть уйма. Внутри индекса документы можно организовать по типам — произвольным именам, описывающим похожие по структуре документы. Наконец, сам документ — это просто JSON. Обычный скучный JSON.
Создание, чтение, обновление и удаление
С двумя абзацами теории разобрались, самое время что-нибудь сделать.
Создание
Добавить документ в elasticsearch так же просто, как и сделать HTTP POST. Ну один в один:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
$ curl -X POST 127.0.0.1:9200/monitor/logs?pretty -d '{
"kind": "info",
"message": "The server is up and running"
}'
#{
# "_index" : "monitor",
# "_type" : "logs",
# "_id" : "AVoWblBE6fU5oFCNC7jY",
# "_version" : 1,
# "result" : "created",
# "_shards" : {
# "total" : 2,
# "successful" : 1,
# "failed" : 0
# },
# "created" : true
#}
|
Мы отправили документ { "kind": "info", "message": "..."} в индекс под названием monitor, и тип с названием logs. Ни индекса, ни типа до этого не существовало, и elasticsearch создал их, взяв названия из URL. Вдобавок, он разродился ответным JSON, в который положил сгенерированный идентификатор документа (_id) и немного других деталей. Кстати, можно задать и свой _id, просто заменив POST на PUT и передав идентификатор в URL. Например, вот так -X PUT monitor/logs/42. Слово ?pretty в строке запроса просто включает форматирование ответов.
Так как добавлять документы по одному то еще удовольствие, можно сразу добавить целую пачку через bulk запрос:
|
1
2
3
4
5
6
|
$ curl -X POST 127.0.0.1:9200/monitor/logs/_bulk -d '
{ "index": {}}
{ "kind" : "warn", "message": "Using 90% of memory" }
{ "index": {}}
{ "kind": "err", "message": "OutOfMemoryException: Epic fail has just happened" }
'
|
В bulk запросе на каждый документ идёт 2 JSON фрагмента. Один показывает, что именно нужно делать с документом (в нашем случае «index»). Второй фрагмент — сам документ.
Чтение
Теперь, раз уж у нас уже есть что-то в индексе, можно запросить что-нибудь назад. Если сделать пустой поиск, то мы получим в ответ всё, что успели добавить:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
curl 127.0.0.1:9200/monitor/_search?pretty
#{
# .….….
# "hits" : {
# "total" : 3,
# "max_score" : 1.0,
# "hits" : [
# {
# "_index" : "monitor",
# "_type" : "logs",
# "_id" : "AVoWe_7d6fU5oFCNC7jb",
# "_score" : 1.0,
# "_source" : {
# "kind" : "err",
# "message" : "OutOfMemoryException: Epic fail has just happened"
# }
# },
# {
# "_index" : "monitor",
# "_type" : "logs",
# "_id" : "AVoWe_7d6fU5oFCNC7ja",
# "_score" : 1.0,
# "_source" : {
# "kind" : "warn",
# "message" : "Using 90% of memory"
# }
# },
# {
# "_index" : "monitor",
# "_type" : "logs",
# "_id" : "AVoWblBE6fU5oFCNC7jY",
# "_score" : 1.0,
# "_source" : {
# "kind" : "info",
# "message" : "The server is up and running"
# }
# }
# ]
# }
#}
|
Но можно запросить конкретный документ по его ID:
|
1
2
3
4
5
6
7
8
|
curl 127.0.0.1:9200/monitor/logs/AVoWblBE6fU5oFCNC7jY?pretty
#{
# …
# "_source" : {
# "kind" : "info",
# "message" : "The server is up and running"
# }
#}
|
Обновление
По аналогии, зная идентификатор документа, можно его обновить. Так как моё начальство нервно относится к фразам в логах вроде «Epic fail has just happened», его стоит заменить на что-нибудь другое:
|
1
2
3
4
|
$ curl -X POST 127.0.0.1:9200/monitor/logs/AVoWe_7d6fU5oFCNC7jb -d '
{ "kind": "err",
"message": "OutOfMemoryException: The server process used all available memory"
}'
|
Но на самом деле в этом случае elasticsearch не обновляет документ, а просто заменяет его на другой, сохраняя прежний ID.
Удаление
Чтобы удалить что-нибудь есть HTTP DELETE. Например,
curl -X DELETE 127.0.0.1:9200/monitor/logs/AVoWe_7d6fU5oFCNC7jb
Поиск
Но добавлять и получать назад JSON умеют многие NoSQL базы. Самая мощная фишка в elasticsearch — это, конечно, поиск. Есть два способа, чтобы искать документы по индексу: REST Request API для простых поисковых запросов, и более серьёзный Query DSL.
REST Request API просто добавляет дополнительный параметр в URL запроса, вроде такого:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
$ curl -s 127.0.0.1:9200/monitor/_search?q=memory | json_pp
#{ .…
# "hits" : {
# "hits" : [
# {
# "_id" : "AVoWe_7d6fU5oFCNC7ja",
# "_source" : {
# "kind" : "warn",
# "message" : "Using 90% of memory"
# },
# .…
# "_score" : 0.2824934
# },
# {
# "_id" : "AVoWe_7d6fU5oFCNC7jb",
# "_source" : {
# "kind" : "err",
# "message" : "OutOfMemoryException: The server process used all available memory"
# },
# …
# "_score" : 0.27233246
# }
# ],
# "total" : 2,
# "max_score" : 0.2824934
# …
#}
|
Но через один ‘q='-параметр сложный запрос не соберешь. В Query DSL, с другой стороны, можно и комбинировать ключевые слова, и собирать булевы выражения, добавлять фильтры — много чего можно сделать, чтобы найти что-то конкретное.
Query DSL поиск это всё тот же HTTP GET запрос, но с немного более замороченным синтаксисом. Например, если мы хотим найти логи, которые так или иначе касаются памяти, но при этом не критичны, можно собрать такой запрос:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
$ curl -s 127.0.0.1:9200/monitor/_search -d '
{
"query": {
"bool": {
"must": [ {
"match": {
"kind":"info warn"
}}, {
"match": {
"message":"memory"
}}
]
}
}
}' | json_pp
#{
# …
# "hits" : {
# "total" : 1,
# "hits" : [
# {
# "_type" : "logs",
# "_index" : "monitor",
# "_source" : {
# "message" : "Using 90% of memory",
# "kind" : "warn"
# },
# "_score" : 0.5753642,
# "_id" : "AVoWe_7d6fU5oFCNC7ja"
# }
# ],
# "max_score" : 0.5753642
# }
#}
|
Агрегирование
В довесок к поиску данные можно еще и агрегировать. Агрегирование само по себе огромный топик, но в качестве примера можно просто посчитать, сколько логов у нас скопилось по категориям:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
curl -s 127.0.0.1:9200/monitor/_search -d '
{
"size": 0,
"aggs": {
"group_by_kind": {
"terms": {
"field" : "kind.keyword"
}
}
}
}' | json_pp
#{
# "aggregations" : {
# "group_by_kind" : {
# "sum_other_doc_count" : 0,
# "buckets" : [
# {
# "key" : "err",
# "doc_count" : 1
# },
# {
# "doc_count" : 1,
# "key" : "info"
# },
# {
# "key" : "warn",
# "doc_count" : 1
# }
# ],
# …
#}
|
Так как _search URL делает и поиск и агрегацию, а ключевые слова для поиска мы не предоставили, в параметры пришлось добавить "size": 0, чтобы запрос не вернул всё коллекцию документов в довесок к статистике.
Завершение
Обычно в этом месте я пишу «сегодня мы едва прошлись по X», но elasticsearch настолько огромный, что даже слово «едва» ошибочно создаёт иллюзию объёма. Обновление документов через отправку скрипта, схемы полей, фильтры, сложные запросы и агрегирование, работа в кластерах, анализаторы документов и куча других вещей — мы их вообще не затронули.
Но и того, что мы посмотрели, надеюсь, должно хватить, чтобы понять: elasticsearch — это вменяемо простой поисковый движок с понятным API и миллионом фич, которые нужно гуглить и гуглить.
=================================================
ИСПОЛЬЗОВАНИЕ ELASTICSEARCH
1. ПРОСМОТР ВЕРСИИ ELASTICSEARCH
Для общения с Elasticsearch используется RESTful API или, если говорить простым языком, обыкновенные HTTP-запросы. И работать с ним мы можем прямо из браузера. Но делать этого не будем, а будем использовать Linux-утилиту curl. Для просмотра информации о сервисе достаточно обратиться по адресу localhost:9200:
curl -XGET http://localhost:9200
Опция -X задаёт протокол, который мы используем. В этой статье мы используем не только GET, но и POST, PUT, DELETE и другие. Если вы только что перезапустили сервис и получаете ошибку "http://localhost:9200 - conection refused", то ничего страшного - система загружается, надо подождать несколько минут.
Если будете пытаться ей помешать, можете потерять уже проиндексированные данные. Просто убедитесь, что сервис уже запущен (active) командой:
sudo systemctl status elasticsearch
2. СПИСОК ИНДЕКСОВ ELASTICSEARCH
Точно так же, как MySQL может иметь несколько баз данных, Elastic может иметь несколько индексов. У каждого из них может быть несколько отдельных таблиц (type), каждая из которых будет содержать документы (doc), которые можно сравнить с записями в таблице MySQL.
Чтобы посмотреть текущий список индексов, используйте команду _cat:
curl 'localhost:9200/_cat/indices?v&pretty'
Общий синтаксис использования глобальных команд такой:
curl 'localhost:9200/_команда/имя?параметр1&параметр2'
- _команда - обычно начинается с подчеркивания и указывает основное действие, которое надо сделать;
- имя - параметр команды, указывает, над чем нужно выполнить действие, или уточняет, что надо делать;
- параметр1 - дополнительные параметры, которые влияют на отображение, форматирование, точность вывода и так далее;
Например, команда _cat также может отобразить общее "здоровье" индексов (health) или список активных узлов (nodes). Параметр v включает более подробный вывод, а pretty сообщает, что надо форматировать вывод в формате json (чтобы было красиво).
3. ИНДЕКСАЦИЯ ДАННЫХ
Вообще, вам не обязательно создавать индекс. Вы можете просто начать записывать в него данные, как будто бы он и таблица уже существует. Программа создаст всё автоматически. Для записи данных используется команда _index. Вот только однострочной команды curl нам будет уже недостаточно, надо добавить ещ сами данные в формате json, поэтому создадим небольшой скрипт:
vi elastic_index.sh
Здесь я записываю данные: индекс app, таблицу data. Так как они не существуют, система их создаст. Как видите, сами данные нам нужно передать в формате json. Передаём заголовок с помощью опции -H, будем отсылать json, а потом с помощью -d передаём сами данные. Данные представляют из себя четыре(точно?, а то я просто вижу 3) поля:
- name - имя;
- age - возраст;
- degree - оценка.
Нам следует ещё остановиться на синтаксисе формата json:
{
"имя_поля" : "значение_поля",
"имя_поля1": "значение_поля",
"имя_поля2": {
"имя_поля3": "значение поля",
"имя_поля4": ["значение1", "значение2"]
}
}
Если вы знакомы с JavaScript, то уже знаете этот формат. Если нет, то ничего страшного, сейчас разберёмся. Данные представляются в виде пар имя: значение. И имя поля, и его значение нужно брать в кавычки и разделять их двоеточием. Каждая пара отделяется от следующей с помощью ?ЭТО ЧТО ЗА ЗВЕРЬ ТАКОЙ?комы&. Но если пар больше нет, то кома не ставится. Причём каждое поле может иметь в качестве значения либо текст, либо ещё один набор полей, заключённый в фигурные скобки {}. Если нужно перечислить два элемента без названия поля, надо использовать не фигурные скобки, а квадратные [] (массив), как в поле4. Для удобства форматирования используйте пробелы, табуляции Elasticsearch не понимает.
Теперь сохраняем скрипт и запускаем:
sh elastic_index.sh
Если всё прошло успешно, то вы увидите такое сообщение:
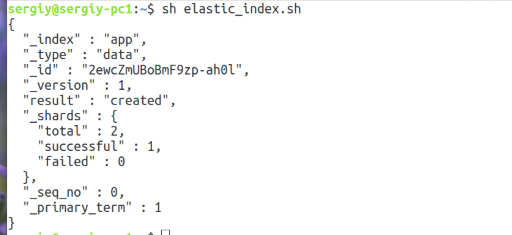
Это значит, что документ добавлен в индекс. Теперь вы можете снова посмотреть список индексов.

4. ИНФОРМАЦИЯ ОБ ИНДЕКСЕ
Мы знаем список созданных индексов, но как посмотреть список типов (таблиц) в индексе и как узнать, какие и каких типов поля созданы в индексе? Для этого можно использовать команду _mapping. Но перед тем, как мы перейдём к ней, надо вернуться к синтаксису. Команды могут применяться как к глобально, так и для отдельного индекса или для отдельного типа. Синтаксис будет выглядеть так:
curl 'localhost:9200/индекс/тип/_команда/имя?параметр1&параметр2'
Чтобы посмотреть все индексы и их поля, можно применить команду глобально:
curl 'localhost:9200/_mapping?pretty'
Или только для индекса app:
curl 'localhost:9200/app/_mapping?pretty'
Только для типа data индекса app:
curl 'localhost:9200/app/data/_mapping?pretty'
В результате программа вернула нам ответ, в котором показан индекс app, в нём есть тип data, а дальше в поле properties перечислены все поля, которые есть в этом типе: age, degree и name. Каждое поле имеет свои параметры.
5. ИНФОРМАЦИЯ О ПОЛЕ И МУЛЬТИПОЛЯ
Каждое поле описывается таким списком параметров:
"age" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
Параметр type - указывает тип поля. В данном случае программа решила, что это текст, хотя это число. Дальше интереснее, у нас есть ещё параметр fields. Он задаёт так называемые подполя или мультиполя. Поскольку Elasticsearch - это инструмент поиска текста, то для обработки текста используются анализаторы, нормализаторы и токенизаторы, которые могут приводить слова к корневой форме, переводить текст в нижний регистр, разбивать текст на отдельные слова или фразы. Вс` это нужно для поиска и по умолчанию применяется к каждому текстовому полю.
Но если вам нужно просто проверить точное вхождение фразы без её изменений, то с проанализированным таким образом полем у вас ничего не получиться. Поэтому разработчики придумали мультиполя. Они содержат те же данные, что и основное поле, но к ним можно применять другие анализаторы, или вообще их не применять. В нашем примере видно, что система автоматически создала подполе типа keyword, которое содержит неизмененный вариант текста.
Таким образом, если вы захотите проверить точное вхождение, то нужно обращаться именно к полю age.keyword а не к age. Или же отключить анализатор для age. Анализаторы выходят за рамки этой статьи, но именно эта информация нам ещё понадобится дальше.
6. УДАЛЕНИЕ ИНДЕКСА
Чтобы удалить индекс, достаточно использовать вместо GET протокол DELTE и передать имя индекса:
curl -XDELETE 'http://localhost:9200/app?pretty'
Теперь индекс удалён. Создадим ещё один такой же вручную.
7. РУЧНОЕ СОЗДАНИЕ ИНДЕКСА
Программа создала для цифр текстовые поля, к ним применяется анализ текста и индексация, а это потребляет дополнительные ресурсы и память. Поэтому лучше создавать индекс вручную и настраивать такие поля, какие нам надо. Первых два поля сделаем int без подполей, а третье оставим как есть. Запрос будет выглядеть так:
vi elastic_createindex.sh
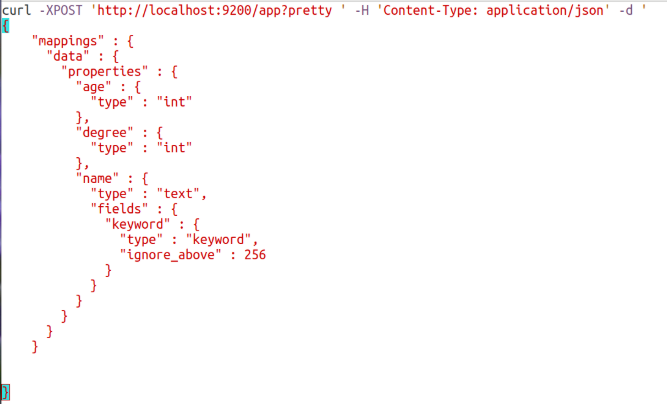
Как видите, здесь используется тот же синтаксис, который программа возвращает при вызове команды _mapping. Осталось запустить скрипт, чтобы создать индекс:
sh elastic_createindex.sh
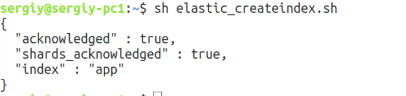
Чтобы всё прошло нормально, необходимо удалить индекс, который был создан автоматически, поэтому предыдущий пункт расположен там не зря. Вы можете менять mappings для существующего индекса, но в большинстве случаев для применения изменений к существующим данным индекс надо переиндексировать. Например, если вы добавляете новое мультиполе, то в нём можно будет работать только с новыми данными. Старые данные, которые были там до добавления, при поиске будут недоступны.
5. МАССОВАЯ ИНДЕКСАЦИЯ ДАННЫХ
Дальше я хотел бы поговорить о поиске, условиях и фильтрации, но чтобы почувствовать полную мощьность всех этих инструментов нам, нужен полноценный индекс. В качестве индекса мы будем использовать один из демонстрационных индексов, в который разложены пьесы Шекспира. Для загрузки индекса наберите:
wget https://download.elastic.co/demos/kibana/gettingstarted/shakespeare_6.0.json
В файле находятся данные в формате json, которые надо проиндексировать. Это можно сделать с помощью команды _bluck:
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/shakespeare/doc/_bulk?pretty' --data-binary @shakespeare_6.0.json
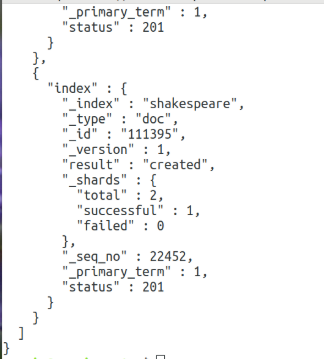
Индексация работает так же, как и при ручном добавлении данных, но благодаря оптимизации команды _bluck, выдаёт результат намного быстрее.
6. ПОИСК ПО ИНДЕКСУ
Для поиска или, другими словами, выборки данных в Elasticsearch используется команда _search. Если вызвать команду без параметров, то будут обрабатываться все документы. Но выведены будут только первые 10, потому что это ограничение по умолчанию:
curl -XGET 'http://localhost:9200/shakespeare/doc/_search?pretty'
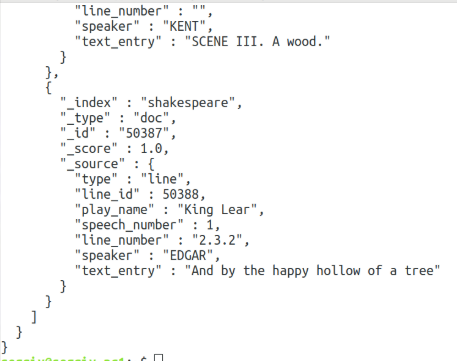
Здесь мы выбрали первые десять документов из индекса shakespeare и таблицы doc. Чтобы выбрать больше, передайте параметр size со значением, например 10000:
curl -XGET 'http://localhost:9200/shakespeare/doc/_search?size=10000&pretty'
Самый простой пример поиска - передать поисковый запрос в параметре q. При этом поиск Elasticsearch будет выполняться во всех полях индекса. Например, найдём все, что касается Эдгара (EDGAR):
curl -XGET 'http://localhost:9200/shakespeare/doc/_search?q=EDGAR&pretty '
Но как вы понимаете, всё это очень не точно и чаще всего надо искать по определённым полям. В Elasticsearch существует несколько типов поиска. Основные из них:
- term - точное совпадение искомой строки со строкой в индексе или термом;
- match - все слова должны входить в строку, в любом порядке;
- match_phrase - вся фраза должна входить в строку;
- query_string - все слова входят в строку в любом порядке, можно искать по нескольким полям, используя регулярные выражения;
Синтаксис term такой:
"query" {
"term" {
"имя_поля": "что искать"
}
}
Например, найдем записи, где говорит Эдгар с помощью term:
vi elastic_searchterm.sh
sh elastic_searchterm.sh
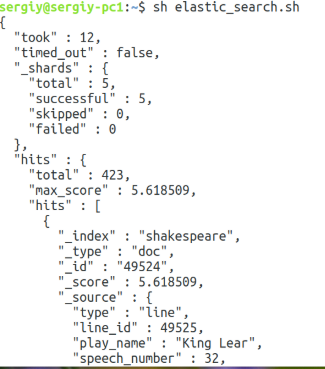
Мы нашли десять реплик, которые должен сказать Эдгар. Дальше испытаем неточный поиск с помощью match. Синтаксис такой же, поэтому я его приводить не буду. Найдём предложения, которые содержат слова of love:

С query_string и match_phrase разберётесь сами, если будет нужно.
8. ОПЕРАТОРЫ AND И OR ДЛЯ ПОИСКА
Если вы хотите сделать выборку по нескольким полям и использовать для этого операторы AND и OR, то вам понадобится конструкция bool. Синтаксис её такой:
"query": {
"bool" : {
"must" : [
{"поле1" : "условие"},
{"поле2" : "условие"},
],
"filter": {},
"must_not" : {}
"should" : {}
}
}
Обратите внимание на синтаксис. Поскольку у нас два элемента подряд, мы используем массив []. Но так как дальше нам снова нужно создавать пары ключ:значение, то в массиве открываются фигурные скобки. Конструкция bool объединяет в себе несколько параметров:
- must - все условия должны вернуть true;
- must_not - все условия должны вернуть false;
- should - одно из условий должно вернуть true;
- filter - то же самое что и match, но не влияет на оценку релевантности.
Например, отберём все записи, где Helen говорит про любовь:
vi elastic_searchbool.sh
Как видите, найдено только два результата.
9. ГРУППИРОВКА
И последнее, о чём мы сегодня поговорим, - группировка записей в Еlasticsearch и суммирование значений по ним. Это аналог запроса GOUP BY в MySQL. Группировка выполняется с помощью конструкции aggregations или aggs. Синтаксис её такой:
"aggregations" : {
"название" : {
"тип_группировки" : {
параметры
},
дочерние_группировки
}
}
Разберём по порядку:
- название - указываем произвольное название для данных, используется при выводе;
- тип_группировки - функция группировки, которая будет использоваться, например terms, sum, avg, count и так далее;
- параметры - поля, которые будем группировать и другие дополнительные параметры;
- дочерние группировки - в каждую группировку можно вложить ещё одну или несколько других таких же группировок, что делает этот инструмент очень мощным.
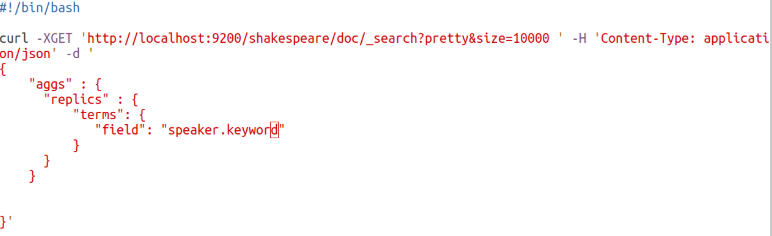
Давайте подсчитаем, сколько отдельных реплик для каждого человека. Для этого будем использовать группировку terms:
vi elastic-group.sh
В результате запроса Еlasticsearch получим:
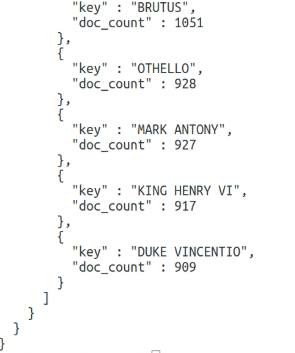
Сначала пойдут все найденные документы, а затем в разделе aggregations мы увидим наши значения. Для каждого имени есть doc_count, в котором содержится количество вхождений этого слова. Чтобы продемонстрировать работу вложенных группировок, давайте найдём сумму и среднее значение поля line_number для каждого участника:

В сумме у нас очень большие числа, поэтому они отображаются в экспоненциальном формате. А вот в среднем значении всё вполне понятно.
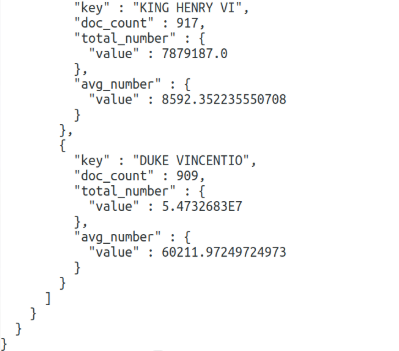
Тут key - имя персонажа, total_number.value - сумма поля, avg_number.value - среднее значение поля.