Thank you for reading this post, don't forget to subscribe!
Terraform делает только одну задачу. И делает её хорошо. Задача эта: создать, собрать и настроить и ввергнуть во тьму ресурсы. Любые ресурсы, которые можно описать в виде набора свойств, понятных провайдеру этих самых ресурсов. В первую очередь речь идёт о ресурсах наших любимых вычислительных облаков. AWS и Azure. И множества других.
Terraform — это не есть единое API для всех облаков.
Зато описания ресурсов будут в текстовом виде. В файлах формата HCL (это нечто среднее между JSON и YAML). В вашей системе контроля версий. Это и называется Infrastructure as Code.
Terraform написан на Go. Так что вся установка сводится к распаковке единственного бинарного файла из архива, прописыванию его в PATH и настройке автодополнения в вашей shell.
Поехали по терминологии.
Конфигурация. Configuration. Это набор *.tf файлов в текущем каталоге, то есть где вы запустили terraform. В этих файлах вы описываете то, что вам нужно создать и поддерживать. Не важно, как вы эти файлы назовёте. Не важно, в каком порядке в них всё опишете. Есть только небольшое соглашение, что должны быть файлы: main.tf — типа заглавные определения, variables.tf — все входные переменные, outputs.tf — все выходные переменные данной конфигурации.
Провайдеры. Providers. Плагины, отдельные бинарники, которые определяют весь остальной набор того, что можно задать в конфигурации. Они скачиваются при инициализации конфигурации. Инициализация делается командой terraform init.
Вот как может выглядеть описание провайдера для амазонового облака (AWS):
|
1 2 3 4 5 |
provider "aws" { version = "~> 1.20" region = "${var.aws_region}" profile = "${var.aws_profile}" } |
Конструкции с фигурными скобками — это interpolations. В данном случае берутся значения двух входных переменных.
Переменные. Variables. Входные значения для вашей конфигурации. Их надо явно описать:
|
1 2 |
variable "aws_profile" {} variable "aws_region" {} |
Переменные бывают трёх типов: строка, список, map. В данном случае тип не указан, и подразумевается строка. С поддержкой вложенных типов, типа списка mapов, всё настолько неопределённо, что лучше считать, что вложенных типов нет.
Значения для переменных, как и положено, можно передавать кучей разных способов. Через переменные окружения типа TF_VAR_aws_profile. Через параметры командной строки типа -var 'aws_profile="terraform"'. Через файлы *.tfvars, которые нужно явно передавать в командной строке: -var-file ../test.tfvars. Через файлы *.auto.tfvars в текущем каталоге, которые подгружаются автоматически. Понятное дело, есть правила переопределения переменных, а mapы даже мержатся.
Есть ещё выходные переменные. Это некоторые значения, которые являются выходом вашей конфигурации. Эти значения потом можно легко получить командой terraform output.
Ресурсы. Resources. То, ради чего всё это и затевается. Ресурсы, поддерживаемые провайдером, которые нужно создать, или модифицировать, или удалить.
У каждого ресурса есть тип, зависящий от провайдера, имя, в контексте данной конфигурации, и набор аргументов, которые нужно передать ресурсу. Также ресурс имеет некоторые атрибуты, это какие-то, возможно, вычисляемые значения, которые становятся известны, когда ресурс создан.
Вот как может выглядеть, например, создание S3 бакета:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
resource "aws_s3_bucket" "frontend_bucket" { bucket = "${var.environment}-frontend" acl = "public-read" website { index_document = "index.html" error_document = "index.html" } tags { Name = "${var.deployment} Frontend" Environment = "${var.environment}" Deployment = "${var.deployment}" } } |
Атрибуты одних ресурсов могут быть указаны как interpolations при создании других ресурсов. Тогда Terraform понимает, что ресурсы имеют зависимость, и создаёт их в правильном порядке.
|
1 2 3 4 5 6 7 8 9 |
resource "aws_cloudfront_distribution" "frontend_s3_distribution" { origin { // вот ссылка на S3 bucket domain_name = "${aws_s3_bucket.frontend_bucket.bucket_domain_name}" origin_id = "S3-${var.environment}-frontend" } //... у CloudFront Distribution ооочень много аргументов } |
Чаще всего ресурсы один в один соответствуют тем ресурсам, что можно создать через API или в консоли управления облаком. Но иногда встречаются и «псевдоресурсы», которые представляют собой команды модификации «настоящих» ресурсов.
Например, Security Groups в AWS. Часто нужно, чтобы одна Security Group ссылалась на другую, а та ссылалась на эту. В консоли это проблем не вызывает, создаём обе, а потом модифицируем права доступа, чтобы они ссылались друг на друга.
Terraform так не умеет. Он считает, что все ресурсы должны быть созданы за один присест, без многошаговых модификаций, в порядке, согласно их зависимостям (а если нет зависимостей, то даже параллельно). А здесь получается циклическая зависимость, которая Terraform не устраивает.
Для решения проблемы придумали «псевдоресурс» aws_security_group_rule, который фактически является шагом модификации «настоящего» ресурса aws_security_group. Циклическая зависимость разрывается. Настоящие ресурсы создаются в несколько шагов.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
// первая security group resource "aws_security_group" "alb_security_group" { name = "${var.environment}-alb-security-group" description = "Allows HTTPS from Anywhere into ALB" vpc_id = "${var.vpc_id}" // здесь правила доступа прописаны внутри ресурса ingress { from_port = 443 to_port = 443 protocol = "tcp" cidr_blocks = [ "0.0.0.0/0" ] ipv6_cidr_blocks = [ "::/0" ] } egress { from_port = 0 to_port = 0 protocol = "-1" // тут ссылаемся на вторую security group security_groups = [ "${aws_security_group.ecs_cluster_security_group.id}" ] } } // вторая security group resource "aws_security_group" "ecs_cluster_security_group" { // тут нет ссылок на первую security group name = "${var.environment}-ecs-cluster-security-group" description = "Allows traffic from ALB" vpc_id = "${var.vpc_id}" } // правило доступа для второй security group resource "aws_security_group_rule" "allow_alb_for_ecs" { security_group_id = "${aws_security_group.ecs_cluster_security_group.id}" type = "ingress" from_port = 0 to_port = 0 protocol = "-1" // вот тут ссылка на первую security group source_security_group_id = "${aws_security_group.alb_security_group.id}" } // еще одно правило доступа для второй security group resource "aws_security_group_rule" "allow_egress_for_ecs" { security_group_id = "${aws_security_group.ecs_cluster_security_group.id}" type = "egress" from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = [ "0.0.0.0/0" ] ipv6_cidr_blocks = [ "::/0" ] } |
Обратите внимание на передачу списков. Почему такие вольности, и почему кавычки обязательны, я не знаю.
|
1 2 3 4 5 6 7 8 9 10 |
// одиночное значение можно обернуть в список list = [ "${var.single}" ] // список можно передать как список list = "${var.list}" // а можно обернуть в скобки list = [ "${var.list}" ] // а можно даже к списку добавить ещё значение list = [ "${var.list}", "${var.single}" ] // или даже объединить два списка list = [ "${var.list1}", "${var.list2}" ] |
Источники данных. Data Sources. Провайдеры умеют не только создавать ресурсы, но и запрашивать атрибуты уже имеющихся ресурсов. Например, чтобы вставить какие-нибудь свойства в ваши ресурсы. Для этого и нужны источники данных.
Но есть и более интересные применения. Например, провайдер template позволяет читать локальные файлы-шаблоны, подставляя туда переменные. Синтаксис шаблонов полностью повторяет синтаксис interpolations. Что довольно убого. Циклов, например, туда не завезли.
Но есть очень интересный способ «добавить» циклы в шаблоны. Дело в том, что и у ресурсов, и у источников данных есть аргумент count. По умолчанию он равен одному, и создаётся ровно один ресурс или источник данных. (Если поставить нуль, то ничего создано не будет). А если поставить больше единицы, то будет создано несколько ресурсов или источников данных. И все атрибуты этих ресурсов или источников данных можно получить в виде списка. Это общая практика в Terraform: по спискам аргументов формировать списки ресурсов. А уж превратить список значений в тот же массив JSON — дело техники.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
// определение провайдера provider "template" { version = "~> 1.0" } data "template_file" "container_definition" { // читаем этот файл template = "${file("${path.module}/container-definition.json")}" // столько раз, сколько у нас задано контейнеров count = "${length(var.containers)}" vars { // тут доступ к элементу списка name = "${element(var.containers, count.index)}" // тут много списков... image = "${element(aws_ecr_repository.repository.*.repository_url, count.index)}" cpu = "${element(var.container_cpu_limits, count.index)}" memory = "${element(var.container_memory_limits, count.index)}" port = "${element(var.container_ports, count.index)}" region = "${var.region}" log_group = "${aws_cloudwatch_log_group.log_group.name}" log_stream_prefix = "${element(var.containers, count.index)}" environment = "${element(var.container_environments, count.index)}" } } resource "aws_ecs_task_definition" "task_definition" { family = "${var.environment}-${var.service}" // тут формируем json array из списка отрендеренных шаблонов container_definitions = "[ ${join(",", data.template_file.container_definition.*.rendered)} ]" requires_compatibilities = ["FARGATE"] network_mode = "awsvpc" cpu = "${var.cpu_limit}" memory = "${var.memory_limit}" execution_role_arn = "${var.ecs_execution_role_arn}" task_role_arn = "${var.ecs_execution_role_arn}" } |
Обратите внимание, для доступа ко всем переменным и атрибутам используется единый синтаксис с префиксами.
var.var_name— значение переменнойresource_type.resource_name.attribute_name— значение атрибута ресурса, определённого в данной конфигурацииresource_type.resource_name.*.attribute_name— список значений атрибутов ресурса, еслиcountбыл больше единицыdata.data_source_type.data_source_name.attribute_name— значение атрибута источника данныхdata.data_source_type.data_source_name.*.attribute_name— список значений атрибутов источника данных, еслиcountбыл больше единицыcount.index— индекс текущей «итерации» «цикла», еслиcountбольше единицыpath.module— путь (в файловой системе) текущего модуляmodule.module_name.module_output— значение выходной переменной модуля
Почти со всеми этими выражениями можно интерактивно поиграть, если выполнить команду terraform console.
Модули. Modules. Любая конфигурация в Terraform может рассматриваться как модуль. Текущая конфигурация, в текущем каталоге, называется root module. Любые другие конфигурации, в других каталогах файловой системы, из реестра модулей от HashiCorp, из репозитория на GitHub или Bitbucket, просто доступные по HTTP, можно подключить к текущей конфигурации и использовать.
При подключении модулю даётся имя. Под этим именем он будет здесь доступен. Нужно указать местоположение модуля. Одно и то же местоположение модуля можно подключать несколько раз под разными именами. Так что думайте об опубликованных конфигурациях как о классах, которые можно переиспользовать. А конкретное подключение здесь можно считать экземпляром класса. Наследования только нет 🙂 Зато делегирование — пожалуйста. Модули могут использовать другие модули.
Кроме имени, модулю при подключении нужно задать аргументы. Это те самые входные переменные. Внутри модуля они будут использоваться как ${var.var_name}. А результат работы модуль предоставляет в виде выходных переменных. На них в данной конфигурации можно ссылаться как ${module.module_name.var_name}. В общем-то, почти аналогично использованию ресурсов.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
// подключаем модуль и даём ему имя "vpc" module "vpc" { // определение модуля берём из локальной ФС двумя уровнями выше source = "../../modules/vpc" // передаём аргументы environment = "${var.environment}" deployment = "${var.deployment}" region = "${var.aws_region}" availability_zones = "${var.aws_availability_zones}" // хардкодим аргументы vpc_cidr = "172.31.0.0/16" public_subnets_cidr = [ "172.31.64.0/24", "172.31.68.0/24", "172.31.69.0/24" ] public_subnets_ipv6_cidr = [ "2600:1f14:ee6:6300::/64", "2600:1f14:ee6:6301::/64", "2600:1f14:ee6:6302::/64" ] private_subnets_cidr = [ "172.31.65.0/24", "172.31.66.0/24", "172.31.67.0/24" ] } // вывод модуля транслируем в вывод данной конфигурации output "public_subnet_ids" { // на вывод модуля ссылаемся так value = [ "${module.vpc.public_subnet_ids}" ] } output "private_subnet_ids" { value = [ "${module.vpc.private_subnet_ids}" ] } |
Резюмируем. Имеем набор *.tf файлов в текущем каталоге. Это — конфигурация. Или root module. Который может подключать другие модули из разных мест. Другие модули — это такие же *.tf файлы. Они принимают переменные и возвращают переменные. По ходу дела описывают ресурсы и используют источники данных.
Имеем полное декларативное описание того, что мы хотим получить. Как это работает?
Состояние. State. Второе, после конфигурации, ключевое понятие Terraform. Состояние хранит состояние ресурсов. Как оно обстоит на самом деле в этом облаке. По умолчанию состояние — это один большой (не сильно большой) JSON файл terraform.tfstate, который создаётся в текущем каталоге.
Этот файл состояния можно хранить в системе контроля версий. Но, если сильно много разработчиков будут править конфигурацию Terraform, состояние тоже будет часто меняться. И придётся постоянно править конфликты, не говоря уже о том, что не стоит забывать делать pull.
Поэтому лучше использовать remote state. Состояние можно хранить в Consul. А, в случае AWS, в S3. Тоже будет один файлик, но в облаке, и с версионированием. И будет всем доступен, и постоянно будет из облака дёргаться. Норм.
Поехали.
Сначала нашу конфигурацию нужно проинициализировать. Команда terraform init выкачивает плугины (провайдеры, бэкенды для remote state), модули (с GitHub, например), и сваливает это в скрытый подкаталог .terraform. Этот подкаталог не нужно хранить в системе контроля версий. Но он нужен для нормальной работы Terraform. Поэтому terraform init -input=false — обязательный шаг, чтобы запускать Terraform из CI.
Вторая команда для использования Terraform в обычной жизни: terraform apply. На самом деле она выполняет несколько шагов.
Шаг первый. Refresh. Terraform сравнивает текущее известное состояние с реальным состоянием ресурсов в облаке. Провайдер производит кучу запросов на чтение через облачное API. И состояние обновляется. При первом запуске состояние является пустым. Значит, обновлять нечего, и Terraform считает, что ни одного ресурса не существует.
Шаг второй. Plan. Terraform сравнивает текущее известное (и только что обновлённое) состояние с конфигурацией. Если в состоянии ресурса нет, а в конфигурации он есть, ресурс будет создан. Если в состоянии ресурс есть, а в конфигурации его нет, ресурс будет удалён. Если изменились аргументы ресурса, то, если это возможно, ресурс будет обновлён на месте. Или же ресурс будет удалён, а на его месте будет создан новый ресурс того же типа, но с новыми аргументами.
План будет представлен пользователю. С полным указанием того, что будет создано, удалено, или изменено. В той мере, насколько это известно до начала настоящего выполнения. (Идентификаторы ресурсов, например, как правило назначаются случайно, и становятся известны лишь после настоящего создания ресурса.) Надо ответить «yes», чтобы перейти к следующему шагу.
Шаг третий. Apply. Собственно, применение плана, созданного на предыдущем шаге. Согласно зависимостям. При этом снова изменяется состояние, туда записываются все настоящие свойства созданных ресурсов.
Ну вот и всё. Всё просто. Сверяемся, сравниваем, высчитываем разницу, накатываем изменения. В отличие от Ansible, сверка состояния делается один раз перед построением плана и для всей конфигурации сразу.
А теперь — нюансы.
Terraform — прост и упрям. И он не делает rollback.
К сожалению, в большинстве случаев создание даже одного ресурса — не атомарно. Даже создание S3 bucket — это с десяток разных вызовов, в основном, чтобы отдельно выяснить разные свойства этого бакета (get запросы). Если какой-то запрос не выполнился (а в моём случае наиболее частой причиной ошибок был недостаток прав на отдельные операции), Terraform считает, что создание ресурса провалилось.
Но в реальности ресурс таки мог создаться. Но это может не найти отражения в состоянии Terraform. И при повторном запуске может случиться повторная попытка создания ресурса, которая может сломаться теперь уже из-за конфликта имён. Или в облаке может оказаться более одного желаемого ресурса.
Кроме того, Terraform совсем не в курсе ресурсов, созданных автоматически при вызове API облака (пример: Elastic Network Interface в AWS создаются неявно). И не в курсе ресурсов, не описанных в конфигурации, но от которых могут зависеть его ресурсы (пример: Security Group в AWS не получится удалить, пока хоть кто-то её использует, но вот кто этот кто, Terraform знать не всегда может).
Но Terraform упрям. Так что после правки прав доступа, правки ошибок в конфигурации, и нескольких запусков terraform apply, облако таки неумолимо перейдёт в желаемое состояние. Плюс может остаться немного мусора — ненужных ресурсов, которые были созданы, но не были удалены. Мусор придётся подчистить ручками.
Потом, полагаю, придёт культура всё делать через Terraform, и сразу угадывать нужные права. И мусора будет меньше.
Можно ли перенести инфраструктуру, набитую ручками в консоли, в Terraform? Можно.
Пишете конфигурацию. Лучше добавлять один ресурс за одним. Делаете terraform import. По сути, вы сопоставляете имена ресурсов в конфигурации (resource_type.resource_name) с реальными идентификаторами существующих ресурсов (они разные для разных типов ресурсов). Terraform пытается прочитать атрибуты ресурсов и записать их в состояние. Делаете terraform plan и смотрите, не пытается ли Terraform что-то поправить. Если пытается, правите конфигурацию, и снова смотрите на план. В идеале Terraform скажет, что всё ок, и ничего править не будет. В случае похуже он всё-таки что-нибудь пересоздаст.
Аналогичным образом, только используя terraform refresh, можно привести конфигурацию в соответствие с теми изменениями, которые кто-то сделал своими шаловливыми ручками. (И ручки потом оторвать).
Импорт не всегда работает идеально. Совсем не работает для «псевдоресурсов», о которых я говорил ранее. Сложности возникают со сложными ресурсами, с множеством вложенных сущностей, вроде тех же Security Group или Route Table в AWS. Но после terraform apply и перетряхивания внутренностей ресурсов в угоду Terraform, всё устаканивается.
Рефакторинг. Рефакторинг конфигурации Terraform. Он возможен. Нужно только действовать аккуратно.
Переименование ресурса. Скорее всего Terraform предложит удалить старый ресурс, и создать новый, с новым именем. Если это неприемлемо, можно попробовать удалить ресурс из состояния командой terraform state rm, а потом сделать terraform import. Есть ещё специальная команда terraform state mv, которая вроде как специально предназначена для этого рефакторинга. Но я с помощью state mv как-то добился стабильного крэша Terraform. С тех пор остерегаюсь.
Разбиение одной большой конфигурации на несколько маленьких. На это есть несколько причин.
Причина первая. terraform apply выполняется не сильно быстро. И чем больше ресурсов имеется в конфигурации, тем медленнее. Ему же надо проверить состояние каждого ресурса, даже если в конфигурации этот ресурс и не менялся. Имеет смысл выделить части конфигурации исходя из частоты изменений и «охвата территории». Скажем, VPC вам придётся настраивать лишь один раз, и потом почти никогда не менять. ECS кластер вы будете создавать каждый раз, когда будет появляться новое окружение, и потом опять без изменений. А сервисы нужно подновлять каждый индивидуально почти при каждом деплое.
Причина вторая. Terraform пока плохо работает с версионируемыми ресурсами. Типичный пример: ECS Task Definition. Этот ресурс нельзя удалить, только пометить как неактивный. Этот ресурс нельзя изменить, только создать новую ревизию. Поэтому на каждый terraform apply будет «удалён» старый Task Definition, и создан новый Task Definition, даже если в конфигурации ничего не менялось. И обновлён ECS Service, который этот Task Definition использует.
Это приведёт к тому, что этот Service обновит и перезапустит свои таски. То есть произойдёт настоящий редеплой. Это хорошо, потому что можно делать редеплой ECS сервисов с помощью Terraform. Это плохо, потому что я не хочу редеплоить все два десятка моих сервисов одновременно по terraform apply одной большой конфигурации. Сервисы нужно выносить в отдельные конфигурации Terraform.
Хорошо. Создать ещё одну папочку с *.tf файлами рядом — не проблема. Перенести туда управление ресурсами с помощью terraform import тоже можно. Но ведь наши сервисы должны кое-что знать о кластере: имя кластера, те же Security Groups, ещё параметров по мелочи.
Конфигурации зависят от других конфигураций. Из более общих конфигураций нужно передать параметры более конкретным конфигурациям. Кластер должен знать о VPC, сервисы должны знать о кластере.
Можно передать всё, что нужно, горстку нужных идентификаторов, ручками. Как входные переменные нашей конфигурации. Будет работать. Если вы правильно скопируете эти идентификаторы.
Но есть более спортивный способ. Если у нас есть remote state, его можно подключить как источник данных, и прочитать выходные переменные совершенно другой конфигурации, чьё состояние мы подключили.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
// наше состояние terraform { backend "s3" { bucket = "my-lovely-terraform" key = "environment/service/terraform.tfstate" region = "eu-west-1" } } // состояние региона data "terraform_remote_state" "region" { backend = "s3" config { bucket = "my-lovely-terraform" // в другом файлике в S3 key = "environment/region/terraform.tfstate" region = "eu-west-1" } } // состояние кластера data "terraform_remote_state" "cluster" { backend = "s3" config { bucket = "my-lovely-terraform" // в другом файлике в S3 key = "environment/cluster/terraform.tfstate" region = "eu-west-1" } } module "service" { source = "../../modules/ecs-service" // ссылаемся на выходные переменные других конфигураций cluster = "${data.terraform_remote_state.cluster.cluster_name}" ecs_execution_role_arn = "${data.terraform_remote_state.cluster.ecs_execution_role_arn}" vpc_id = "${data.terraform_remote_state.region.vpc_id}" subnet_ids = "${data.terraform_remote_state.region.private_subnet_ids}" security_group_ids = [ "${data.terraform_remote_state.cluster.cluster_security_group_id}", "${data.terraform_remote_state.region.security_group_ids}" ] //... в этом модуле у меня ещё много аргументов } |
Кроме модулей, у нас появляется возможность держать конфигурацию более-менее независимых кусков ресурсов отдельно. Это может быть удобно.
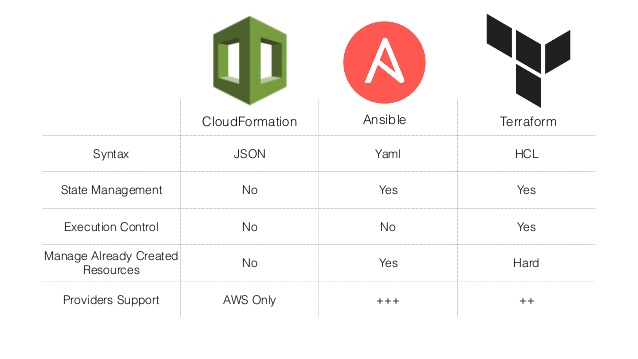
Terraform не заменяет Ansible, а дополняет его. Terraform создаёт ресурсы (виртуальные машины, где угодно), а Ansible настраивает их (через ssh). Другое дело, что если ресурсы — Docker контейнеры, то их и настраивать (изнутри) не нужно.