Thank you for reading this post, don't forget to subscribe!
Имеется Prometheus сервер, запущенный через Prometheus Operator в Kubernetes-кластере,
Prometheus сервера в каждом Kubernetes-кластере через Prometheus federation отправляют данные на центральный сервер.
При больших нагрузках, например на нашем Kubernetes Dev кластере, где очень много подов, Prometheus начинает падать с ошибками:
|
1 |
level=error ts=2021-03-31T07:31:18.765Z caller=federate.go:192 component=web msg=»federation failed» err=»write tcp 10.21.46.181:9090->10.21.53.14:62098: write: broken pipe» |
Либо постоянно уходит в рестарт:
|
1 2 3 4 |
level=info ts=2021-03-31T07:31:26.901Z caller=main.go:827 msg=»Completed loading of configuration file» filename=/etc/prometheus/config_out/prometheus.env.yaml level=info ts=2021-03-31T07:31:26.901Z caller=main.go:646 msg=»Server is ready to receive web requests.» level=warn ts=2021-03-31T07:32:06.364Z caller=main.go:524 msg=»Received SIGTERM, exiting gracefully…» level=info ts=2021-03-31T07:32:06.364Z caller=main.go:547 msg=»Stopping scrape discovery manager…» |
А при удалении — зависает в статусе Terminating:
|
1 2 3 |
prometheus-prometheus-prometheus-oper-prometheus-0 3/3 Terminating 9 46m |
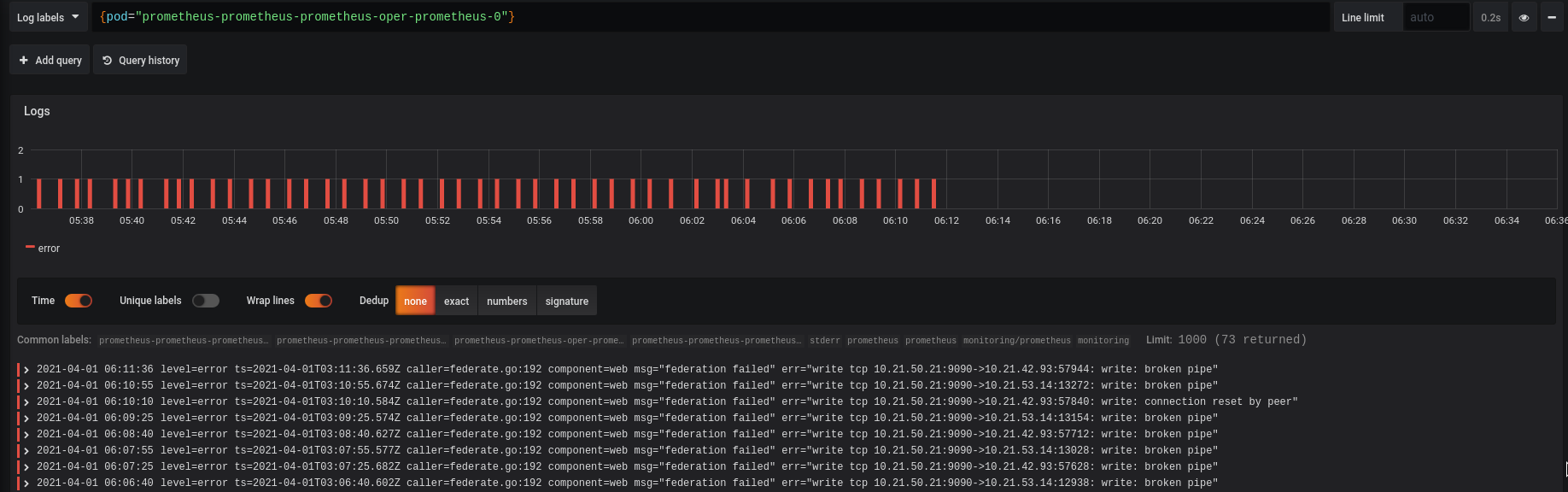
federation failed: write: broken pipe
Сначала разберёмся с broken pipe.
Возникает она из-за того, что при передаче больших данных в federation центральный Prometehus-сервер, который делает запрос к своим таргетам, роль которых выполняют Prometehus-инстансы в Kubernetes-кластерах, слишком долго ожидает от них завершения передачи, и закрывает соединение.
Для решения — изменим параметр scrape_timeout в файле /etc/prometheus.yaml ,у которого дефолтное значение 10 секунд:
|
1 2 3 4 5 |
global: scrape_interval: 1m scrape_timeout: 30s ... |
И результат:
Received SIGTERM, exiting gracefully и рестарты
Решаем вторую проблему — Received SIGTERM, exiting gracefully и зависание пода Prometheus при shutdown.
Проверяем Kubernetes events:
|
1 2 3 4 5 6 7 |
... 35m Normal Created Pod Created container prometheus 35m Normal Started Pod Started container prometheus 29s Warning Unhealthy Pod Liveness probe failed: Get http://10.21.46.181:9090/-/healthy: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 10m Warning Unhealthy Pod Readiness probe failed: Get http://10.21.46.181:9090/-/ready: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 35m Normal Killing Pod Container prometheus failed liveness probe, will be restarted ... |
Как вариант — под не успевает подняться, прочитать базу, и его Kubernetes его убивает, так как превышены значения для Liveness и Readiness probes.
Изменим его параметры:
- изменим
readinessProbe, увеличимinitialDelaySecondsдо 1 минуты - уменьшим срок хранения данных: вместо дефолтных 10 дней оставим 1 час, так как все данные уходят на центральный Prometheus, и на локальных серверах они особо не нужны
- и вместо одного пода будем запускать три реплики
Обновляем Ansible-task, которая вызывает helm-плагин для установки Prometheus Operator, задаём новые параметры:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
... # check available values: https://github.com/prometheus-community/helm-charts/blob/main/charts/kube-prometheus-stack/values.yaml prometheusSpec: resources: requests: memory: 2000Mi cpu: 1000m retention: 1h replicas: 3 externalLabels: ekscluster: {{ eks_env }} containers: - name: prometheus readinessProbe: initialDelaySeconds: 60 failureThreshold: 300 ... |
Деплоим — и теперь работает стабильно.