Thank you for reading this post, don't forget to subscribe!
“10 часов дебаггинга и попыток сделать и посмотреть, что получится, сэкономят вам 10 минут чтения документации“.
Elastic Stack: обзор компонентов
Elastic Stack, он же ELK (Elasticsearch + Logstash + Kibana) наверно наиболее широкоизвеcтная и самая используемая система для сбора и анализа логов, метрик и других данных о состоянии систем – серверов, кластеров, клаудов.
Состоит из трёх основных компонентов:
- Elasticsearch: база данных с возможностями быстрого поиска используя Elasticsearch Index
- Logstash: система сбора данных из разных источников, их трансформации и передачи логов в Elasticsearch
- Kibana: веб-интерфейс для отображения данных из базы Elasticsearch
Кроме того, для ELK (по привычке уже буду его называть так) существует набор т.н. Beats – утилит для сбора данных. Среди них, например, Filebeat – для сбора данных из файлов (логов), или Metricbeat для сбора данных о системе – CPU, RAM и т.д.
Схема работы стека следующая:
- сервер генерирует данные, например логи
- данные собираются локальным Beat-приложением, для логов это будет Filebeat (хотя это необязательный компонент, и логи можно собирать самим Logstash), и отправляет их в Logstash или напрямую в Elastisearch
- Logstash собирает данные из различных источников (получая их от Beats или собирая напрямую), при необходимости выполняет трансформацию (добавление-удаление полей, тегов и т.д.), и отправляет их в Elasticsearch
- Elasticsearch занимается хранением данных с возможностью быстрого поиска
- Kibana предоставляет веб-интерфейс для работы с Elasticsearch (и множество других интеграций, но тут мы их рассматривать не будем)
Создание ЕС2
Устанавливать будем на Ubuntu 20.04 на EC2 в AWS.
Поднимем “голую систему” – без Docker и Kubernetes, настроим всё прямо на хосте.
Используем стандартный подход – Elasticsearch для хранения, Filebeat для сбора логов, Logstash для передачи в Elastic, Kibana для визуализации.
Переходим в AWS Console > EC2 > Instances, запускаем новый, выбираем Ubuntu:

Тип инстанса возьмём c5.2xlarge – 4 ядра и 8 гиг памяти, т.к. Elasticsaerch – это Java с её любовью к памяти и CPU, а Logstash – JRuby, который тоже не слишком экономит ресурсы сервера:

Сеть оставляем по-умолчанию (или выбираем отдельную VPC, если есть): снова-таки – это тестовый инстанс, поэтому нам тут сеть особо роли не играет:
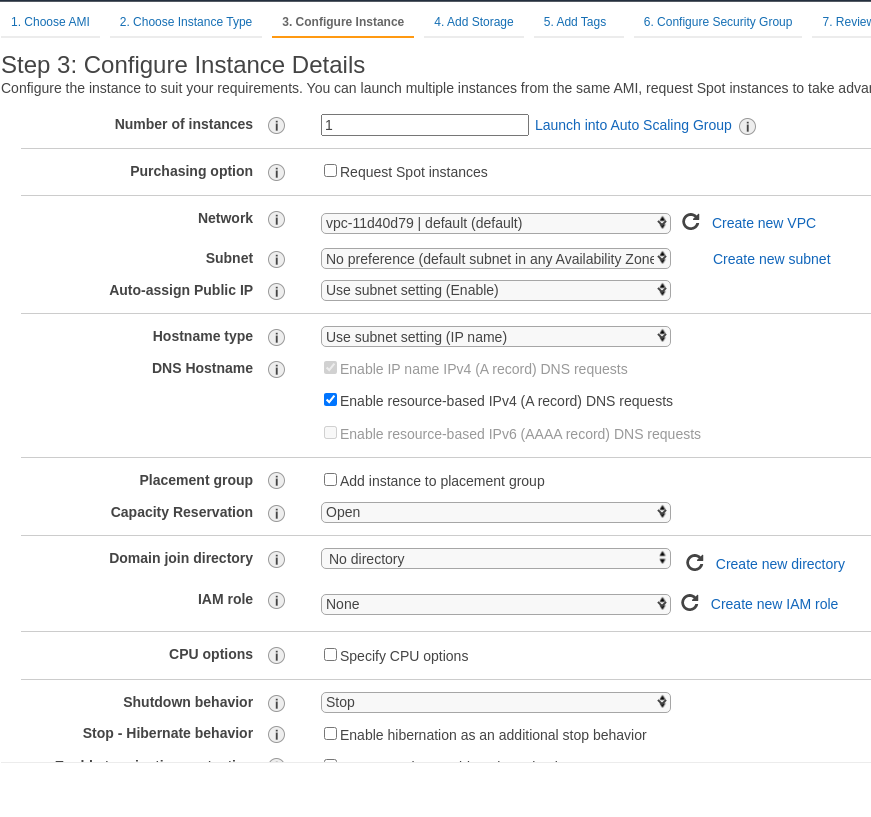
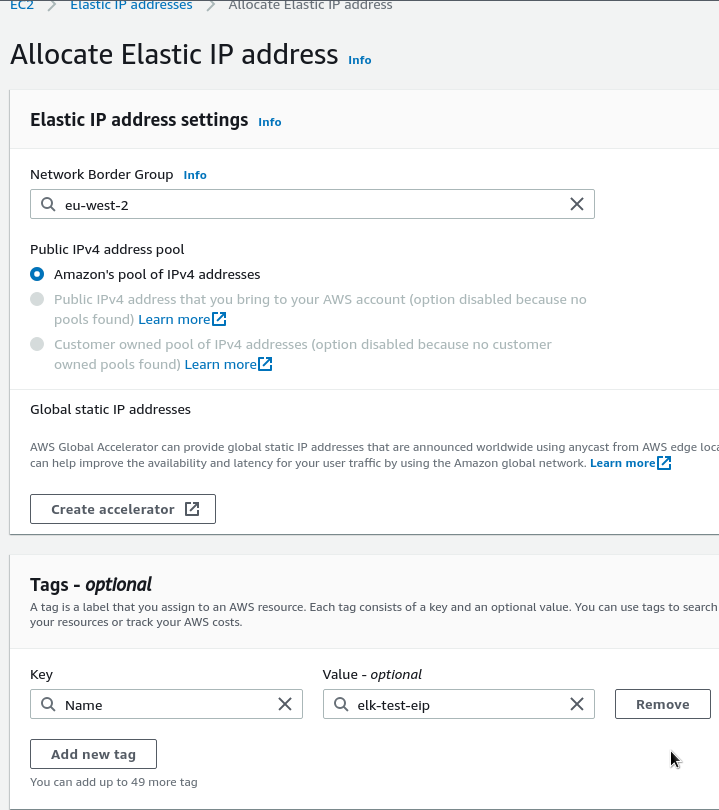
Попотоме добавим Elastic IP, что бы не менялся при перезагрузке.
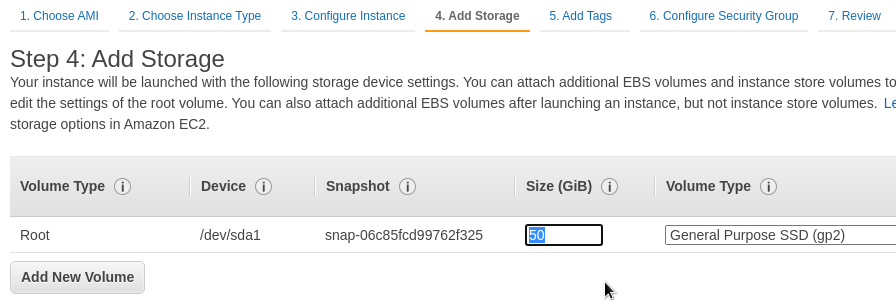
Диск с дефолтных 8 гиг увеличим до 50:
В SecurityGroup открываем SSH и 5601 (порт Kibana) с вашего IP:
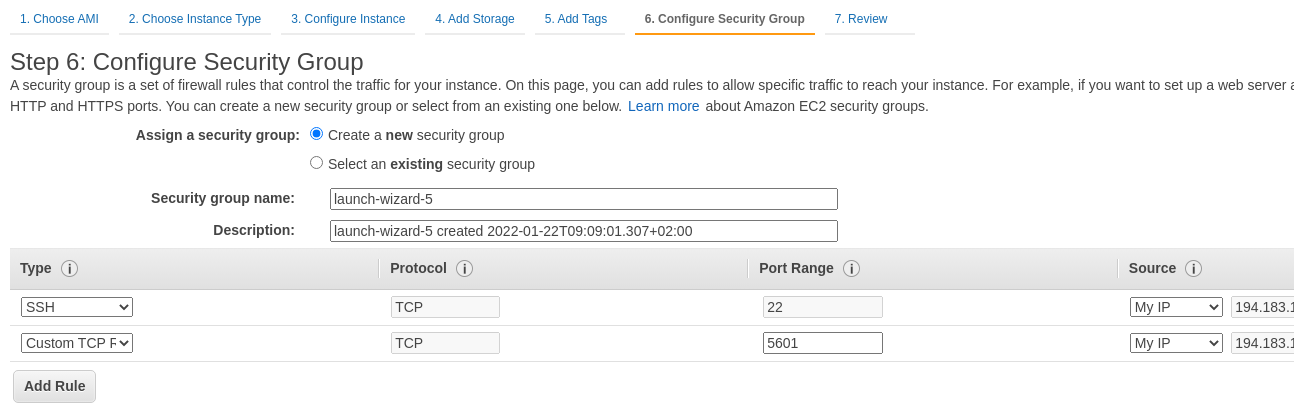
В более полноценном сетапе у нас перед Kibana должен быть NGINX или какой-то Ingress-контроллер в случае Kubernetes, на котором будет SSL. Сейчас запускаем “as is”.
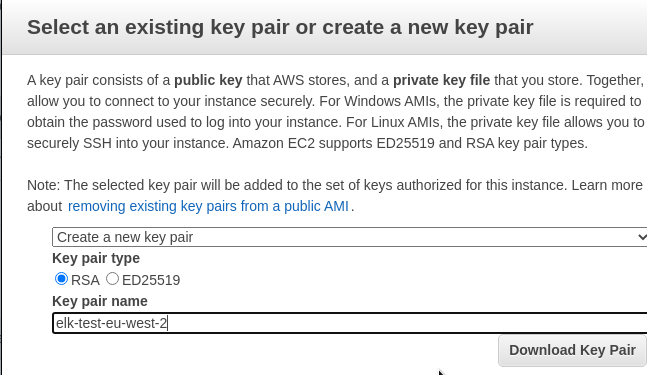
Создаём новый ключ (hint: хорошая идея в имени ключа указывать регион), сохраняем его:
Переходим в Elastic IP addresses, получаем адрес:
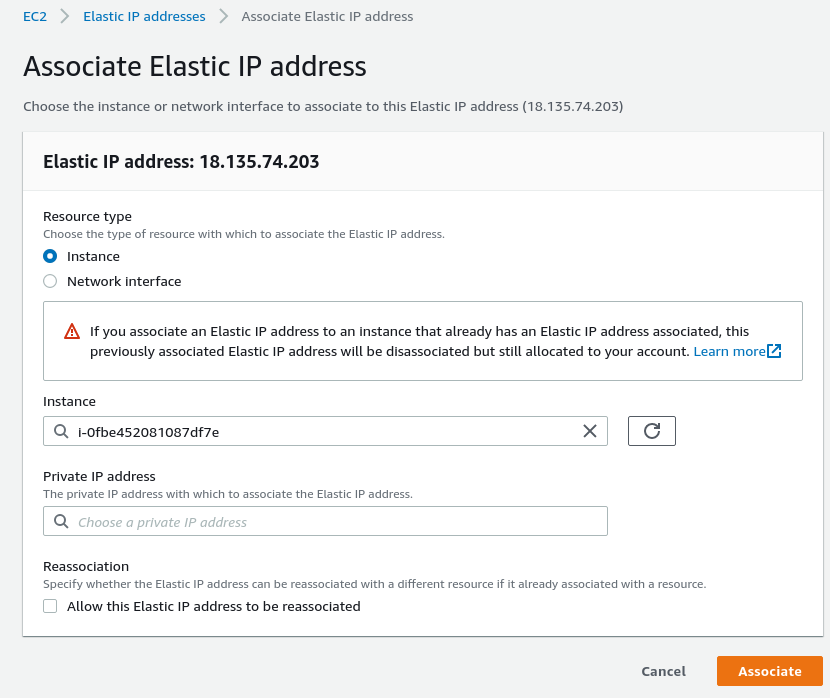
Подключаем его к нашему инстансу:

На рабочей машине меняем права доступа к ключу – оставляем доступ только своему пользователю:
Проверяем подключение:
Обновляем систему:
Ребутаемся, что бы загрузить новое ядро после апгрейда системы:
Переходим к установке компонентов ELK.
Установка Elastic Stack/ELK
Добавляем репозиторий Elasticsearch:
|
1 2 3 4 |
root@ip-172-31-43-4:/home/ubuntu# wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - OK root@ip-172-31-43-4:/home/ubuntu# apt -y install apt-transport-https root@ip-172-31-43-4:/home/ubuntu# sh -c 'echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" > /etc/apt/sources.list.d/elastic-7.x.list' |
Установка Elasticsearch
Устанавливаем пакет elasticsearch:
Файл настроек Еластики – /etc/elasticsearch/elasticsearch.yml.
Добавляем в конец файла discovery.type: single-node – наш Elasticsearch будет работать в виде одной ноды, а не кластера.
При необходимости изменений параметров JVM – редактируем /etc/elasticsearch/jvm.options.
Как минимум, там можно указать минимум и максимум памяти через опции -Xms и -Xmx, хотя он их задаёт автоматически в зависимости от доступной памяти на сервера.
Пока можно оставить по-умолчанию.
Настройка аутентификации и пользователей описана в Set up minimal security for Elasticsearch, мы сейчас этим заниматься не будем – хватит ограничений по IP, которые мы задали в SecurityGroup нашего EC2.
Запускаем сервис, добавляем в автозагрузку:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
root@ip-172-31-43-4:/home/ubuntu# curl -X GET "localhost:9200" { "name" : "ip-172-31-43-4", "cluster_name" : "elasticsearch", "cluster_uuid" : "8kVCdVRySfKutRjPkkVr5w", "version" : { "number" : "7.16.3", "build_flavor" : "default", "build_type" : "deb", "build_hash" : "4e6e4eab2297e949ec994e688dad46290d018022", "build_date" : "2022-01-06T23:43:02.825887787Z", "build_snapshot" : false, "lucene_version" : "8.10.1", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" } |
Логи доступны в каталоге /var/log/elasticsearch, а данные хранятся в /var/lib/elasticsearch.
Elasticsearch Index
Кратко рассмотрим что такое индексы в Elastiseacrh, и как с ними работать через API.
По сути, индекс в Еластике можно представлять себе как базу данных в СУБД типа MySQL, которая хранит документы, а документ в свою очередь представляет собой JSON-объект определённого типа.
Индексы состоят из shards – сегментов, которые могут располагаться на одной и более рабочих нод Еластика, но шардирование и кластеризацию рассмотрим в другой раз.
Просмотр индексов
Для просмотра индексов вызываем GET _cat/indices?v:
Сейчас у нас тут только один служебный (точка в начале имени) индекс .geoip_databases, содержащий список блоков IP и связанных с ними регионов – это дефолтный индекс, с которым идёт Elastiseacrh. Его потом можно будет применить например для добавления региона юзера в NGINX Access Logs.
Создание индекса
Добавим новый пустой индекс:
|
1 2 3 4 5 6 |
root@ip-172-31-43-4:/home/ubuntu# curl -X PUT localhost:9200/example_index?pretty { "acknowledged" : true, "shards_acknowledged" : true, "index" : "example_index" } |
проверим
|
1 2 3 4 |
root@ip-172-31-43-4:/home/ubuntu# curl localhost:9200/_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .geoip_databases 2E8sIYX0RaiqyZWzPHYHfQ 1 0 42 0 40.4mb 40.4mb yellow open example_index akWscE7MQKy_fceS9ZMGGA 1 1 0 0 226b 226b |
example_index – наш новый индекс появился.
И сам индекс:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
root@ip-172-31-43-4:/home/ubuntu# curl localhost:9200/example_index?pretty { "example_index" : { "aliases" : { }, "mappings" : { }, "settings" : { "index" : { "routing" : { "allocation" : { "include" : { "_tier_preference" : "data_content" } } }, "number_of_shards" : "1", "provided_name" : "example_index", "creation_date" : "1642848658111", "number_of_replicas" : "1", "uuid" : "akWscE7MQKy_fceS9ZMGGA", "version" : { "created" : "7160399" } } } } } |
Создание документа в индексе
Добавим документ:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
root@ip-172-31-43-4:/home/ubuntu# curl -H 'Content-Type: application/json' -X POST localhost:9200/example_index/document1?pretty -d '{ "name": "Just an example doc" }' { "_index" : "example_index", "_type" : "document1", "_id" : "rhF0gX4Bbs_W8ADHlfFY", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 2, "_primary_term" : 1 } |
И проверим всё содержимое индекса:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
root@ip-172-31-43-4:/home/ubuntu# curl localhost:9200/example_index/_search?pretty { "took" : 3, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 2, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "example_index", "_type" : "document1", "_id" : "qxFzgX4Bbs_W8ADHTfGi", "_score" : 1.0, "_source" : { "name" : "Just an example doc" } }, { "_index" : "example_index", "_type" : "document1", "_id" : "rhF0gX4Bbs_W8ADHlfFY", "_score" : 1.0, "_source" : { "name" : "Just an example doc" } } ] } } |
И используя его ID – получим содержимое:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
root@ip-172-31-43-4:/home/ubuntu# curl -X GET 'localhost:9200/example_index/document1/qxFzgX4Bbs_W8ADHTfGi?pretty' { "_index" : "example_index", "_type" : "document1", "_id" : "qxFzgX4Bbs_W8ADHTfGi", "_version" : 1, "_seq_no" : 0, "_primary_term" : 1, "found" : true, "_source" : { "name" : "Just an example doc" } } |
Поиск в индексе
Или поищем его в этом индексе по полю name и части содержимого – слову “doc“:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
root@ip-172-31-43-4:/home/ubuntu# curl -H 'Content-Type: application/json' -X GET 'localhost:9200/example_index/_search?pretty' -d '{ "query": { "match": { "name": "doc" } } }' { "took" : 2, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 2, "relation" : "eq" }, "max_score" : 0.18232156, "hits" : [ { "_index" : "example_index", "_type" : "document1", "_id" : "qxFzgX4Bbs_W8ADHTfGi", "_score" : 0.18232156, "_source" : { "name" : "Just an example doc" } }, { "_index" : "example_index", "_type" : "document1", "_id" : "rhF0gX4Bbs_W8ADHlfFY", "_score" : 0.18232156, "_source" : { "name" : "Just an example doc" } } ] } } |
Удаление индекса
Передаём DELETE и имя имя индекса, который хотим удалить:
|
1 2 |
root@ip-172-31-43-4:/home/ubuntu# curl -X DELETE localhost:9200/example_index {"acknowledged":true} |
Окей – тут потрогали, увидели, что есть внутри – идём дальше, переходим к установке Logstash.
Установка Logstash
Устанавливаем Logstash – он есть в репозитории, который добавляли в начале:
Запускаем:
Общий файл настроек Logstash – /etc/logstash/logstash.yml, а для наших конфигов – испольузем /etc/logstash/conf.d/.
Свой output (stdout) он пишет в файл /var/logs/syslog.
Работа с Logstash pipelines
См. How Logstash Works.
Pipelines в Logstash описывают цепочку Input > Filter > Output.
В Input может быть, к примеру, file, stdin или beats.
Logstash Input и Output
Что бы увидеть, как вообще работает Logstash – сначала создадим пайплайн, который через stdin принимает данные, и выводит их через stdout.
Самый простой способ протестировать это – запустить logstash, и указать ему параметры прямо в командной строке через опцию -e:
|
1 2 3 4 5 6 7 8 9 10 |
root@ip-172-31-43-4:/home/ubuntu# /usr/share/logstash/bin/logstash -e 'input { stdin { } } output { stdout {} }' ... The stdin plugin is now waiting for input: Hello, World! { "message" => "Hello, World!", "@version" => "1", "@timestamp" => 2022-01-22T11:30:33.971Z, "host" => "ip-172-31-43-4" } |
Logstash Filter: grok
Очень базовый пример работы с фильтрами на примере фильтра grok.
Создаём файл logstash-test.conf:
|
1 2 3 4 5 6 7 8 9 10 11 |
input { stdin { } } filter { grok { match => { "message" => "%{GREEDYDATA}" } } } output { stdout { } } |
Тут в filter мы используем grok, который ищет совпадение в тексте сообщения. Для поиска grok использует паттерны с регулярными выражениями, в нашем примере паттерн GREEDYDATA соответствует регулярке .*, т.е. любые символы.
Запустим ещё раз, но теперь вместо -e используем -f и передаём имя файла настроек:
|
1 2 3 4 5 6 7 8 9 10 |
root@ip-172-31-43-4:/home/ubuntu# /usr/share/logstash/bin/logstash -f logstash-test.conf ... The stdin plugin is now waiting for input: Hello, Grok! { "message" => "Hello, Grok!", "@timestamp" => 2022-01-22T11:33:49.797Z, "@version" => "1", "host" => "ip-172-31-43-4" } |
Теперь попробуем выполнить трансформацию документа – добавим тег “Example”, и два поля: в одном будет просто текст “Example value“, во втором – подставим время, когда получено сообщение:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
input { stdin { } } filter { grok { match => { "message" => "%{GREEDYDATA:my_message}" } add_tag => ["Example"] add_field => [ "example_field", "Example value" ] add_field => [ "received_at", "%{@timestamp}" ] } } output { stdout { } } |
Запускаем:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
root@ip-172-31-43-4:/home/ubuntu# /usr/share/logstash/bin/logstash -f logstash-test.conf ... Hello again, Grok! { "message" => "Hello again, Grok!", "host" => "ip-172-31-43-4", "tags" => [ [0] "Example" ], "received_at" => "2022-01-22T11:36:46.893Z", "my_message" => "Hello again, Grok!", "@timestamp" => 2022-01-22T11:36:46.893Z, "example_field" => "Example value", "@version" => "1" } |
Logstash Input: file
Тут тоже всё вроде ясно-понятно – попробуем что-то поинтереснее, например – читать данные из файла /var/log/syslog.
Для начала посмотрим содержимое файла:
Что у нас тут есть:
- дата и время –
Jan 22 11:41:49 - хост –
ip-172-31-43-4 - имя программы –
logstash - PID процесса –
8099 - и само сообщение
В фильтре используем тот же grok, которому в условии match зададим паттерны – вместо GREEDYDATA, который заносит всё в поле my_message используем SYSLOGTIMESTAMP, который сработает на значение Jan 21 14:06:23, и это значение будет добавлено в поле syslog_timestamp, затем SYSLOGHOST, DATA, POSINT и оставшуюся часть сообщения получаем с помощью GREEDYDATA, которую сохарним в поле syslog_message.
Кроме того, добавим два поля – received_at и received_from, в которые внесём данные полученные в macth, а затем для примера возможностей удалим оригинальное поле message, так как само сообщение мы уже сохранили в поле syslog_message:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
input { file { path => "/var/log/syslog" } } filter { grok { match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" } add_field => [ "received_at", "%{@timestamp}" ] add_field => [ "received_from", "%{host}" ] remove_field => "message" } } output { stdout { } } |
Запускаем:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
root@ip-172-31-43-4:/home/ubuntu# /usr/share/logstash/bin/logstash -f logstash-test.conf ... { "host" => "ip-172-31-43-4", "path" => "/var/log/syslog", "received_at" => "2022-01-22T11:48:27.582Z", "syslog_message" => "#011at usr.share.logstash.lib.bootstrap.environment.<main>(/usr/share/logstash/lib/bootstrap/environment.rb:94) ~[?:?]", "syslog_timestamp" => "Jan 22 11:48:27", "syslog_program" => "logstash", "syslog_hostname" => "ip-172-31-43-4", "@timestamp" => 2022-01-22T11:48:27.582Z, "syslog_pid" => "9655", "@version" => "1", "received_from" => "ip-172-31-43-4" } ... |
Окей, всё это отлично – а как на счёт Elastisearch?
Logstash output: elasticsearch
Теперь попробуем записать эти данные в Elastisearch:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
input { file { path => "/var/log/syslog" } } filter { grok { match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" } add_field => [ "received_at", "%{@timestamp}" ] add_field => [ "received_from", "%{host}" ] remove_field => "message" } } output { elasticsearch { hosts => ["localhost:9200"] } stdout { } } |
Запускаем, и проверяем индексы Elastic – Logstash должен создать свой индекс:
|
1 2 3 4 5 |
root@ip-172-31-43-4:/home/ubuntu# curl localhost:9200/_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .geoip_databases 2E8sIYX0RaiqyZWzPHYHfQ 1 0 42 0 40.4mb 40.4mb yellow open logstash-2022.01.22-000001 ekf_ntRxRiitIRcmYI2TOg 1 1 0 0 226b 226b yellow open example_index akWscE7MQKy_fceS9ZMGGA 1 1 2 1 8.1kb 8.1kb |
logstash-2022.01.22-000001 – “Ага, вот эти ребята!” (с)
Поищем – что там есть, например – должны быть записи из файла /var/log/syslog о процессе logstash:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
root@ip-172-31-43-4:/home/ubuntu# curl -H 'Content-Type: application/json' localhost:9200/logstash-2022.01.22-000001/_search?pretty -d '{ "query": { "match": { "syslog_program": "logstash" } } }' { "took" : 3, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 36, "relation" : "eq" }, "max_score" : 0.33451337, "hits" : [ { "_index" : "logstash-2022.01.22-000001", "_type" : "_doc", "_id" : "9BGogX4Bbs_W8ADHCvJl", "_score" : 0.33451337, "_source" : { "syslog_program" : "logstash", "received_from" : "ip-172-31-43-4", "syslog_timestamp" : "Jan 22 11:57:18", "syslog_hostname" : "ip-172-31-43-4", "syslog_message" : "[2022-01-22T11:57:18,474][INFO ][logstash.runner ] Starting Logstash {\"logstash.version\"=>\"7.16.3\", \"jruby.version\"=>\"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 11.0.13+8 on 11.0.13+8 +indy +jit [linux-x86_64]\"}", "host" : "ip-172-31-43-4", "@timestamp" : "2022-01-22T11:59:40.444Z", "path" : "/var/log/syslog", "@version" : "1", "syslog_pid" : "11873", "received_at" : "2022-01-22T11:59:40.444Z" } }, ... |
Yay! It works!
Идём дальше.
Установка Filebeat
Устанавливаем пакет:
Файл настроек – /etc/filebeat/filebeat.yml.
По-умолчанию Filebeat будет слать данные напрямую в Elastisearch:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
... # ================================== Outputs =================================== # Configure what output to use when sending the data collected by the beat. # ---------------------------- Elasticsearch Output ---------------------------- output.elasticsearch: # Array of hosts to connect to. hosts: ["localhost:9200"] # Protocol - either `http` (default) or `https`. #protocol: "https" # Authentication credentials - either API key or username/password. #api_key: "id:api_key" #username: "elastic" #password: "changeme" ... |
Обновляем его конфиг – включим сбор логов из /var/log/syslog, и вместо записи в Elastic отправим данные в Logstash.
Добавляем наблюдение за логами, не забываем указать enabled: true:
|
1 2 3 4 5 6 7 8 9 10 |
... filebeat.inputs: ... - type: filestream ... enabled: true ... paths: - /var/log/syslog ... |
Комментируем блок output.elasticsearch, раскоментируем output.logstash:
|
1 2 3 4 5 6 7 8 9 10 11 |
... # ---------------------------- Elasticsearch Output ---------------------------- #output.elasticsearch: # Array of hosts to connect to. # hosts: ["localhost:9200"] ... # ------------------------------ Logstash Output ------------------------------- output.logstash: ... hosts: ["localhost:5044"] ... |
Для Logstash создадим файл
/etc/logstash/conf.d/beats.conf:
|
1 2 3 4 5 6 7 8 9 10 11 |
input { beats { port => 5044 } } output { elasticsearch { hosts => ["http://localhost:9200"] index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } } |
В параметрах
elasticsearch указываем его хост и имя для индекса, в который будем писать данные.
Запускаем Logstash:
Проверяем /var/log/syslog:
Запускаем Filebeat:
Проверяем индексы Еластики:
|
1 2 3 4 5 6 |
root@ip-172-31-43-4:/home/ubuntu# curl localhost:9200/_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .geoip_databases 2E8sIYX0RaiqyZWzPHYHfQ 1 0 42 0 40.4mb 40.4mb yellow open filebeat-7.16.3-2022.01.22 fTUTzKmKTXisHUlfNbobPw 1 1 7084 0 14.3mb 14.3mb yellow open logstash-2022.01.22-000001 ekf_ntRxRiitIRcmYI2TOg 1 1 50 0 62.8kb 62.8kb yellow open example_index akWscE7MQKy_fceS9ZMGGA 1 1 2 1 8.1kb 8.1kb |
filebeat-7.16.3-2022.01.22 – есть новый индекс.
Установка Kibana
Устанавливаем:
Редактируем файл /etc/kibana/kibana.yml, задаём server.host==0.0.0.0, что бы Kibana была доступна из мира.
Запускаем:
Проверяем в браузере:
 Статус –
Статус – /status:
Кдикаем Explore on my own, переходим в Management > Stack management:
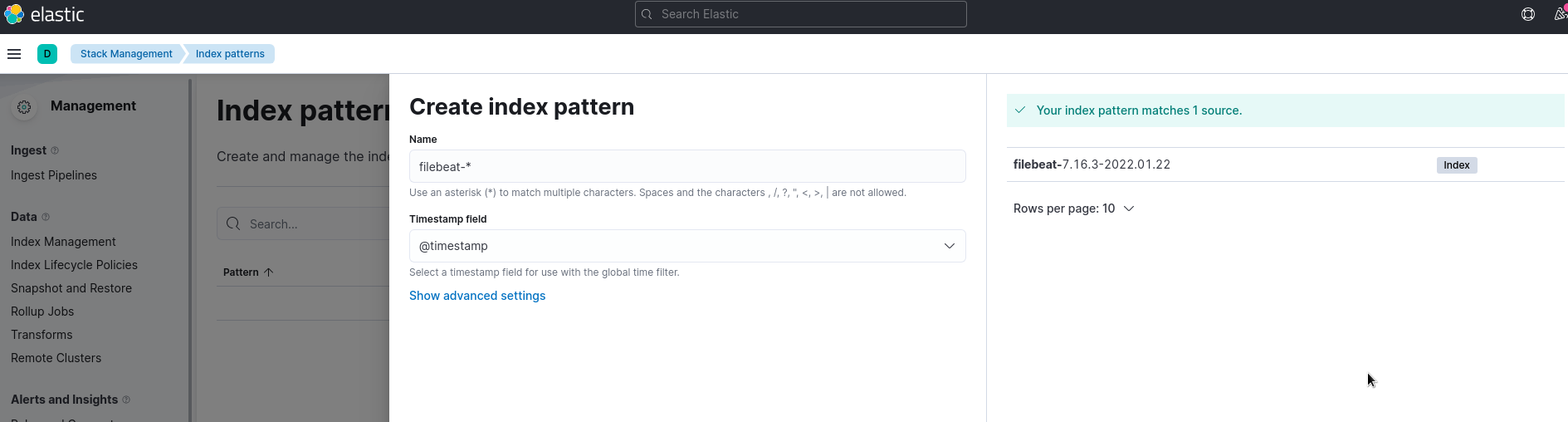
Переходим в Index patterns, создаём новый индекс для Kibana используя маску filebeat-* – справа видим, что Кибана уже нашла все индексы в Elastiseacrh:
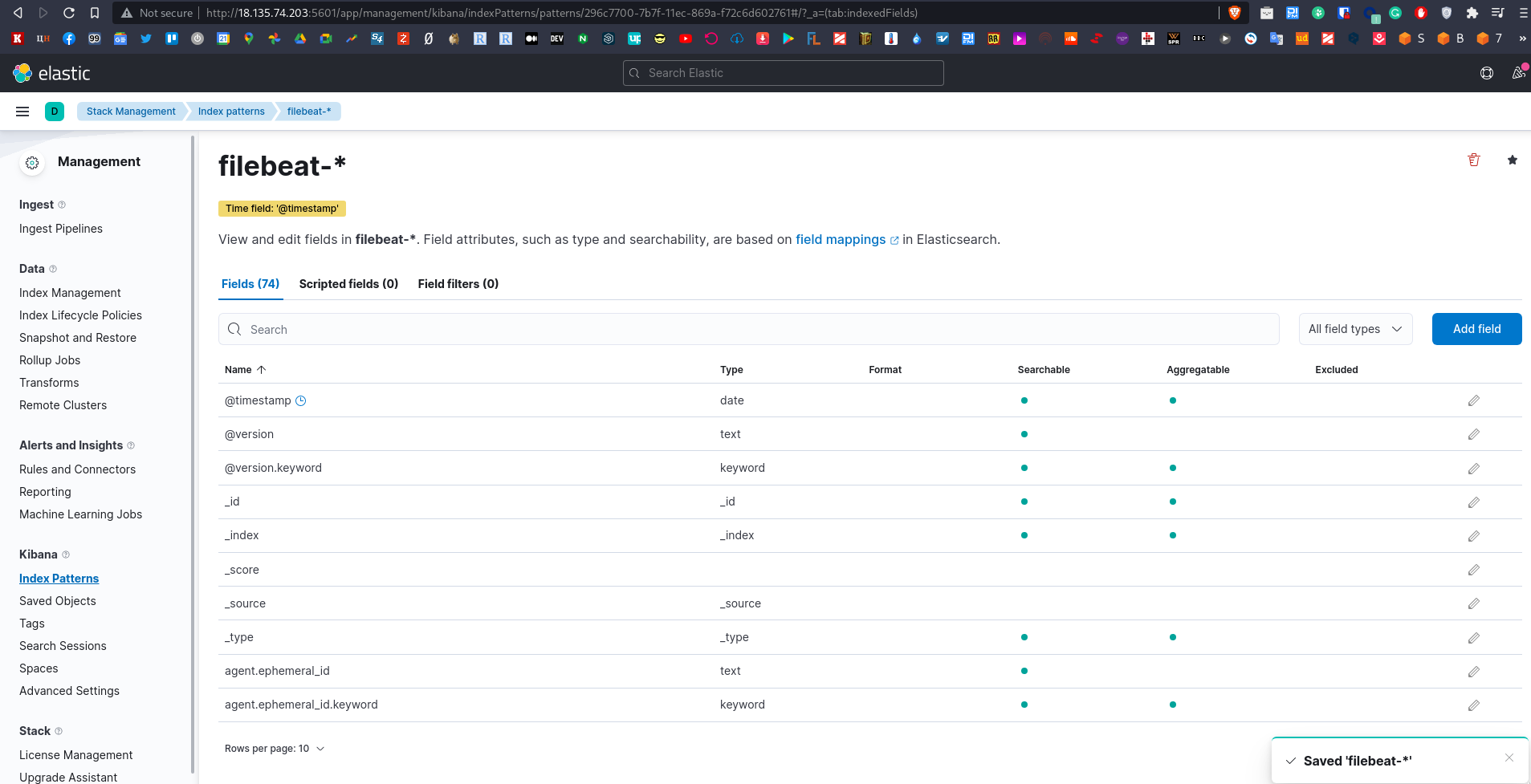
И видим все поля, проиндексированные Кибаной:
Переходим в Observability – Logs:
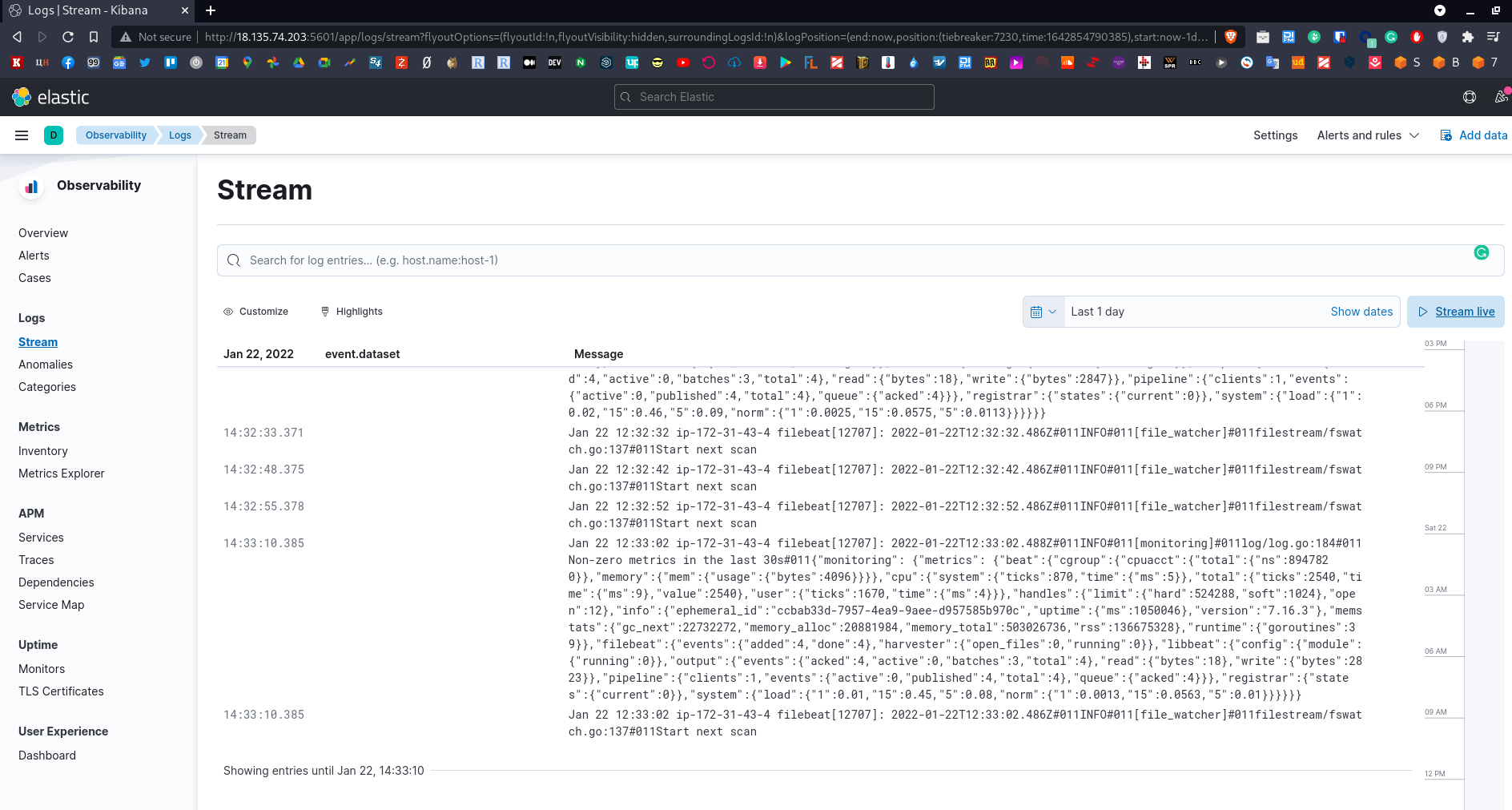
И видим наш /var/log/syslog:
Logstash, Filebeat и NGINX: пример настройки
Ну и давайте сделаем что-то приближённое к реальности:
- установим NGINX
- настроим Filebeat на сбор его логов
- настроим Logstash на их приём и отправку в Elastic
- и посмотрим, что мы увидим в Kibana
Устанавливаем NGINX:
Его файлы логов:
Проверяем его работу:
И access.log:
Okay.
Настройка Filebeat Inputs
Документация – Configure inputs и Configure general settings.
Редактируем блок filebeat.inputs, к сбору данных из /var/log/syslog добавим ещё два инпута – для access и error логов NGINX:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
... # ============================== Filebeat inputs =============================== filebeat.inputs: - type: filestream enabled: true paths: - /var/log/syslog fields: type: syslog fields_under_root: true scan_frequency: 5s - type: log enabled: true paths: - /var/log/nginx/access.log fields: type: nginx_access fields_under_root: true scan_frequency: 5s - type: log enabled: true paths: - /var/log/nginx/error.log fields: type: nginx_error fields_under_root: true scan_frequency: 5s ... |
Тут мы используем тип инпута log, и добавляем поле type: nginx_access/nginx_error.
Настройка Logstash
Удалим старый конфиг и пишем новый, и обновляем /etc/logstash/conf.d/beats.conf:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
input { beats { port => 5044 } } filter { if [type] == "syslog" { grok { match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" } add_field => [ "received_at", "%{@timestamp}" ] add_field => [ "received_from", "%{host}" ] remove_field => "message" } } } filter { if [type] == "nginx_access" { grok { match => { "message" => "%{IPORHOST:remote_ip} - %{DATA:user} \[%{HTTPDATE:access_time}\] \"%{WORD:http_method} %{DATA:url} HTTP/%{NUMBER:http_version}\" %{NUMBER:response_code} %{NUMBER:body_sent_bytes} \"%{DATA:referrer}\" \"%{DATA:agent}\"" } } } date { match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ] } geoip { source => "remote_ip" target => "geoip" add_tag => [ "nginx-geoip" ] } } output { if [type] == "syslog" { elasticsearch { hosts => ["localhost:9200"] index => "logstash-%{+YYYY.MM.dd}" } } if [type] == "nginx_access" { elasticsearch { hosts => ["localhost:9200"] index => "nginx-%{+YYYY.MM.dd}" } } stdout { } } |
В нём описываем:
inputна порт 5044 для filebeat- два
filter:- первый проверяет поле
type, если оно == syslog, то парсит данные, а разделяет их по полям лога/var/log/syslog - второй проверяет поле
type, если оно == nginx_access, то парсит содержимое, и разносит данные по полям access-лога NGINX
- первый проверяет поле
outoutиспользует два условияif, и в зависимости от типа данных отправляет документы в индексlogstash-%{+YYYY.MM.dd}илиnginx-%{+YYYY.MM.dd}
Перезапускаем Logstash и Filebeat:
Запустим curl на постоянные запросы к NGINX, что бы сгенерить access-логи:
Проверяем индексы:
|
1 2 3 4 5 6 |
root@ip-172-31-43-4:/home/ubuntu# curl localhost:9200/_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size ... yellow open logstash-2022.01.28 bYLp_kI3TwW3sPfh7XpcuA 1 1 213732 0 159mb 159mb ... yellow open nginx-2022.01.28 0CwH4hBhT2C1sMcPzCQ9Pg 1 1 1 0 32.4kb 32.4kb |
Ага, индекс появился.
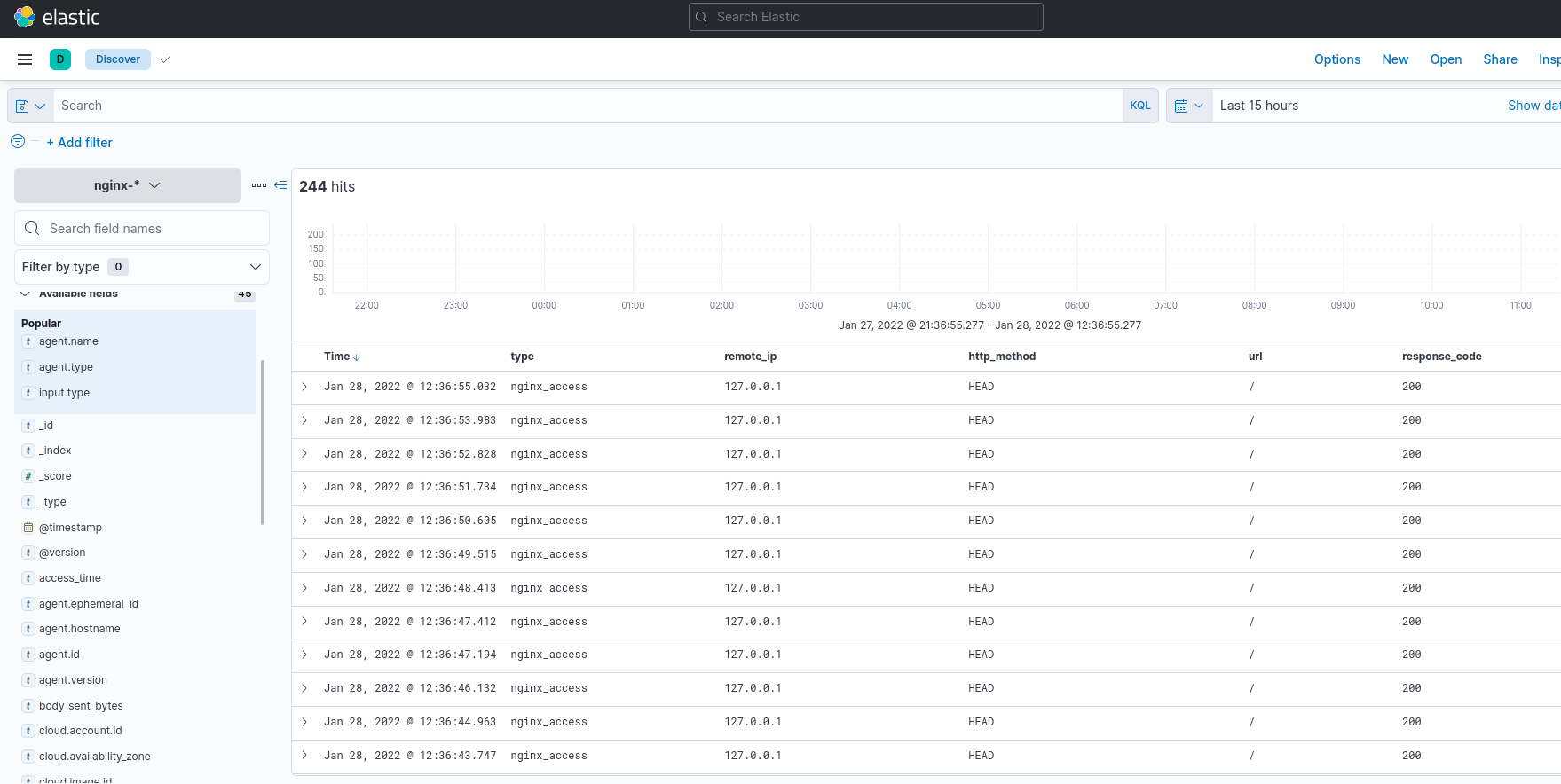
Идём в Kibana, к уже имеющемуся nginx-* добавляем logstash-*:
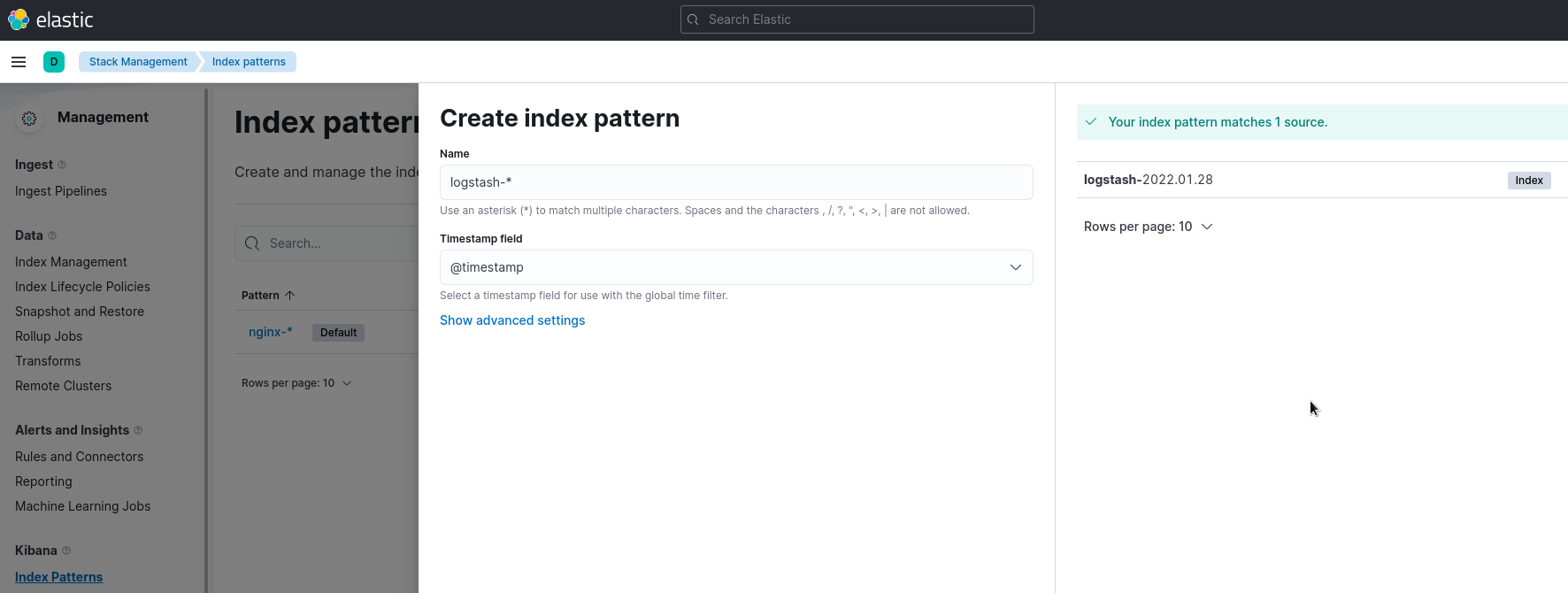
Переходим в Analitycs > Discover, выбираем индекс, смотрим данные:
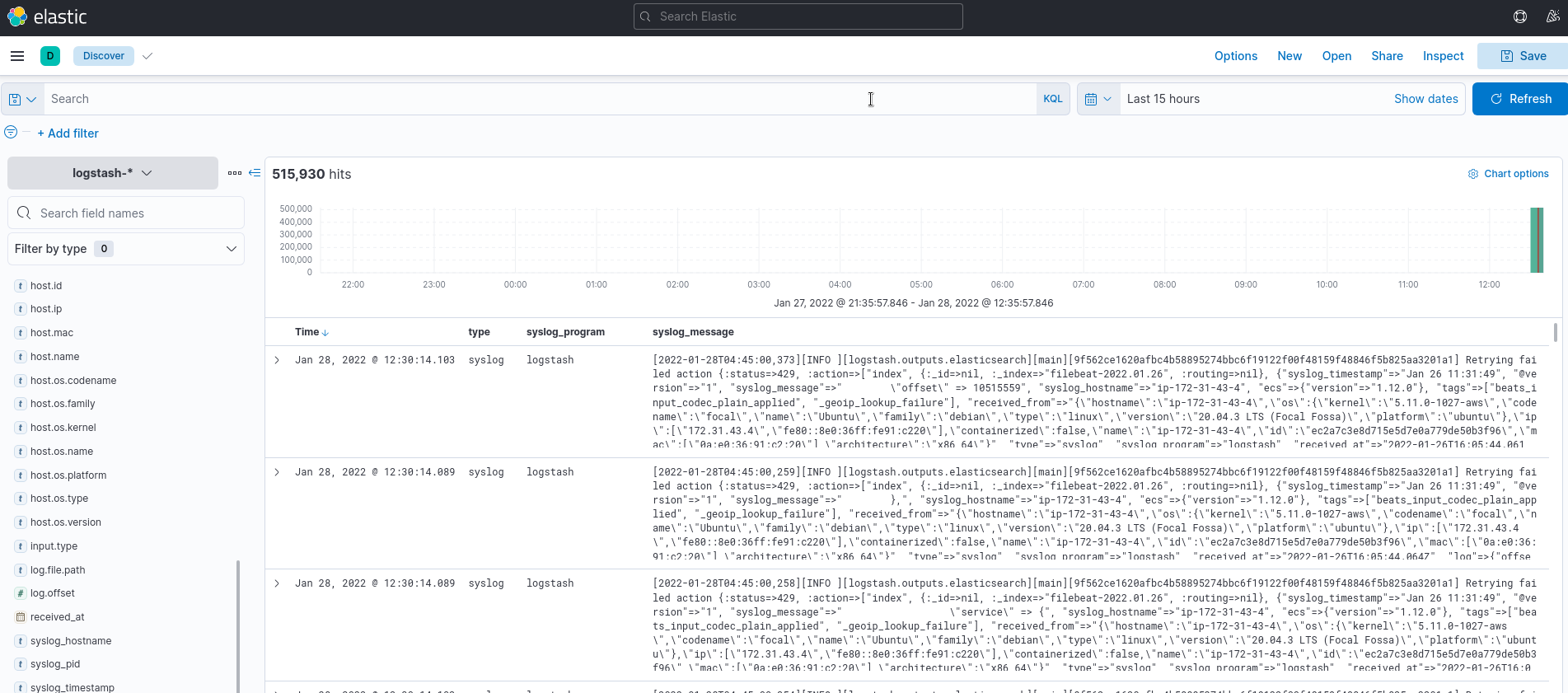
И аналогично – логи NGINX: