Thank you for reading this post, don't forget to subscribe!
Регистрация на хостинге
Для работы с хостинг-провайдером нам заранее понадобятся авторизационные данные и идентификаторы ресурсов. Их мы будем прописывать в сценариях terraform.
Нам нужно зарегистрироваться на сервисе Yandex.Cloud (в нашем примере, мы будем работать, именно, с ним). После этого, нам нужно получить:
1. OAuth-токен. Используется в процедуре аутентификации для получения IAM-токена и нужен нам для прохождения авторизации при подключении terraform. Выдается на 1 год. Получить можно, отправив запрос со страницы документации Яндекс.
2. Идентификатор облака. После регистрации на хостинге мы заходим в контроль-панель. Мы должны увидеть наши ресурсы, в частности, облако:
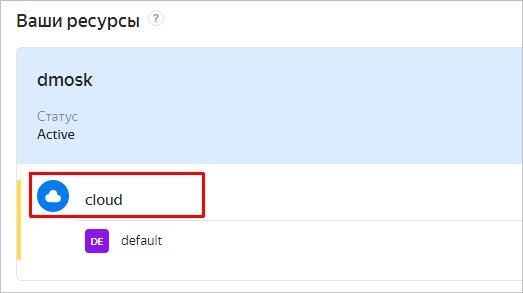
А справа от него будет идентификатор.
3. Идентификатор каталога. На той же странице контроль панели, ниже облака мы увидим каталог:
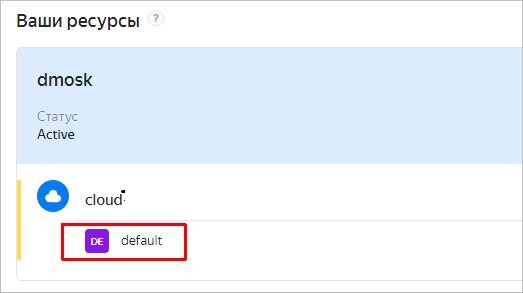
Также, справа мы можем скопировать его идентификатор.
После получения нужных данных просто сохраняем их в отдельный файл. После установки terraform они нам понадобятся.
Установка Terraform
Terraform является клиентом и необходимо выполнить установку на компьютер, с которого планируется управление инфраструктурой. Актуальная инструкция по развертыванию представлена на официальном сайте. На текущий момент клиент может быть установлен из репозитория, с использованием бинарника, собран из исходников, а также с помощью choco на Windows или brew на Mac OS. В нашем примере будут рассмотрены установка на Ubuntu и Rocky Linux из репозитория, а также загрузка бинарника.
Ubuntu (Debian)
Обновляем список пакетов:
apt update
Установим дополнительные пакеты:
apt install gnupg software-properties-common curl
* где:
- gnupg — программа для шифровки и дешифровки цифровых подписей. Нужна для работы с репозиториями.
- software-properties-common — утилита для работы с репозиториями.
- curl — отправка GET, POST и других запросов.
Установим в систему ключ для репозитория:
curl -fsSL https://apt.releases.hashicorp.com/gpg | apt-key add -
Добавляем репозиторий:
apt-add-repository "deb [arch=amd64] https://apt.releases.hashicorp.com $(lsb_release -cs) main"
Обновляем список пакетов, чтобы загрузить списки с нового репозитория:
apt update
Можно устанавливать terraform:
apt install terraform
Rocky Linux
Устанавливаем утилиту для работы с репозиториями:
yum install yum-utils
Добавляем репозиторий:
yum-config-manager --add-repo https://rpm.releases.hashicorp.com/RHEL/hashicorp.repo
Устанавливаем terraform:
yum install terraform
Скачиваем бинарник
Суть данного метода — скачать бинарный файл и перенести его в каталог /usr/local/bin.
Таким же образом устанавливаем terraform на Windows.
Для начала нам понадобятся утилиты unzip и wget. Устанавливаются они по-разному, в зависимости от дистрибутива Linux.
а) Ubuntu / Debian:
apt install unzip wget
б) Rocky Linux:
yum install unzip wget
Переходим к загрузке бинарного файла. Посмотреть ссылку на него можно на странице официального сайта:
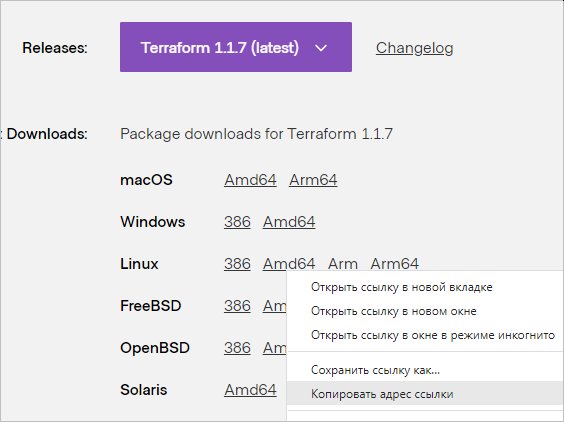
Воспользуемся ссылкой, чтобы скачать архив:
wget https://releases.hashicorp.com/terraform/1.1.7/terraform_1.1.7_linux_amd64.zip
* в нашем примере будет загружена версия 1.1.7.
Распакуем архив командой:
unzip terraform_*_linux_amd64.zip
Перенесем распакованный бинарник в каталог:
mv terraform /usr/local/bin/
После установки
Убедимся, что terraform работает. Для этого вводим команду:
terraform -version
Мы должны получить что-то на подобие:
Terraform v1.1.7
on linux_amd64
Также рекомендуется установить автоподстановки:
terraform -install-autocomplete
Это позволит нам завершать команды terraform с помощью клавиши Tab.
Теперь создадим каталог, в котором будем работать со сценариями для тераформа:
mkdir -p /opt/terraform/yandex
* в моем примере я решил работать в каталоге /opt/terraform/yandex.
Перейдем в созданный каталог:
cd /opt/terraform/yandex
Мы готовы приступить непосредственно к работе с terraform.
Установка провайдера
Чтобы terraform мог корректно взаимодействовать с инфраструктурой провайдера, необходимо использовать набор инструкций, которые будет использовать наша утилита. В терминологии terraform это называется провайдер.
На сайте Hashicorp можно найти все поддерживаемые провайдеры. Как говорилось выше, мы будем работать с Yandex.Cloud. Рассмотрим подробнее установку провайдера для работы с ним.
В нашем рабочем каталоге создаем первый файл:
vi main.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
terraform { required_version = "= 1.1.7" required_providers { yandex = { source = "yandex-cloud/yandex" version = "= 0.73" } } } provider "yandex" { token = "<OAuth>" cloud_id = "<идентификатор облака>" folder_id = "<идентификатор каталога>" zone = "<зона доступности по умолчанию>" } |
* где:
- terraform required_version — версия клиента terraform, для которого должен запускаться сценарий. Параметр не обязательный, но является правилом хорошего тона и может помочь избежать некоторых ошибок, которые возникнут из-за несовместимости при работе в команде.
- required_providers version — версия провайдера. Мы можем указать, как в данном примере, необходимость использовать конкретную версию, а можно с помощью знака >= или <= указать не выше или не ниже определенной.
- token — OAuth-токен для прохождения авторизации. Был нами получен после регистрации на хостинге
- cloud_id — идентификатор для облака, в котором будут создаваться ресурсы. Также получен был нами заранее.
- folder_id — идентификатор каталога, который также был получен в начале инструкции.
- zone — ресурсы, которые хранятся на мощностях Яндекс разделены по зонам. Каждая зона — это определенная географическая локация центра обработки данных. Список доступных зон можно посмотреть на странице Зоны доступности.
Теперь выполним команду:
terraform init
Система загрузит нужные файлы и установит провайдер:
|
1 2 3 4 5 6 7 8 9 |
Initializing the backend... Initializing provider plugins... - Finding latest version of yandex-cloud/yandex... - Installing yandex-cloud/yandex v0.73.0... - Installed yandex-cloud/yandex v0.73.0 (self-signed, key ID E40F590B50BB8E40) ... Terraform has been successfully initialized! ... |
Мы готовы двигаться дальше.
Работа с ресурсами
Мы рассмотрим небольшие примеры по созданию, редактированию и удалению ресурсов. В большей степени мы будем работать с виртуальными машинами. Большую часть информации по написанию сценариев можно найти на официальном сайте хостинга или самого terraform.
Создание ресурсов
В нашем рабочем каталоге создадим новый файл:
vi infrastructure1.tf
Напишем минимально необходимый сценарий для создания виртуальной машины:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
data "yandex_compute_image" "ubuntu_image" { family = "ubuntu-2004-lts" } resource "yandex_compute_instance" "vm-test1" { name = "test1" resources { cores = 2 memory = 2 } boot_disk { initialize_params { image_id = data.yandex_compute_image.ubuntu_image.id } } network_interface { subnet_id = yandex_vpc_subnet.subnet_terraform.id nat = true } metadata = { user-data = "${file("./meta.yml")}" } } resource "yandex_vpc_network" "network_terraform" { name = "net_terraform" } resource "yandex_vpc_subnet" "subnet_terraform" { name = "sub_terraform" zone = "ru-central1-a" network_id = yandex_vpc_network.network_terraform.id v4_cidr_blocks = ["192.168.15.0/24"] } |
* где:
- data — позволяет запрашивать данные. В данном примере мы обращаемся к ресурсу yandex_compute_image с целью поиска идентификатора образа, с которого должна загрузиться наша машина.
- yandex_compute_image — ресурс образа. Его название определено провайдером.
- ubuntu_image — произвольное название ресурса. Его мы определили сами и будем использовать в нашем сценарии.
- ubuntu-2004-lts — в нашем примере мы запрашиваем данные ресурса, который ищем по family с названием ubuntu-2004-lts. Данное название можно посмотреть в контроль панели хостинга — нужно выбрать образ и кликнуть по нему. Откроется страница с дополнительной информацией. В данном случае ubuntu-2004-lts соответствуем Ubuntu 20.04 LTS.
- resource — позволяет создавать различные ресурсы.
- yandex_compute_instance — ресурс виртуальной машины. Его название определено провайдером.
- vm-test1 — наше название ресурса для виртуальной машины.
- yandex_vpc_network — ресурс сети, определенный провайдером.
- network_terraform — наше название для ресурса сети.
- yandex_vpc_subnet — ресурс подсети, определенный провайдером.
- subnet_terraform — наше название для ресурса подсети.
- metadata — обратите особое внимание на передачу метеданных. В данном примере мы передаем содержимое файла, а сам файл рассмотрим ниже.
** в нашем примере будет создана виртуальная машина с названием test1, 2 CPU, 2 Gb RAM в сети 192.168.15.0/24 на базе Ubuntu 20.04 LTS.
*** обратите внимание, что мы указали идентификатор той подсети для виртуальной машины, которую создали также с помощью нашего сценария terraform.
Создаем файл с метеданными:
meta.yml
|
1 2 3 4 5 6 7 8 |
#cloud-config users: - name: test groups: sudo shell: /bin/bash sudo: ['ALL=(ALL) NOPASSWD:ALL'] ssh-authorized-keys: - ssh-rsa AAAAB3Nza..................UXFDCb/ujrK4KbpCyvk= |
* в данном файле мы опишем пользователя, под которым мы сможем подключиться к нашему серверу по SSH:
- #cloud-config — как выяснилось, этот комментарий обязательный.
- name — имя пользователя, который будет создан на виртуальной машине.
- groups — в какую группу добавить пользователя.
- shell — оболочка shell по умолчанию.
- sudo — правило повышения привилений.
- ssh-authorized-keys — список ключей, которые будут добавлены в authorized_keys.
Попробуем испытать наш сценарий. Сначала вводим:
terraform plan
Если мы не ошиблись, утилита покажет, что terraform сделает в нашей облачной инфраструктуре. Очень важно внимательно просматривать изменения.
После того, как мы убедимся в корректности действий, применяем настройку:
terraform apply
Мы еще раз увидим, что будет выполнено, а также получим запрос на подтверждение действий — вводим yes:
Enter a value: yes
Terraform выполнит необходимые действия. Мы можем перейти в контроль-панель хостинга и убедиться, что наша виртуальная машина создалась.
Редактирование данных
Если необходимо внести изменения в нашу инфраструктуру, то достаточно просто открыть наш файл со сценарием:
vi infrastructure1.tf
Внести нужные изменения, например:
|
1 2 3 4 5 6 |
... resources { cores = 4 memory = 4 } ... |
* в нашем конкретном случае, мы увеличили количество процессоров и объем памяти для созданной виртуальной машины.
Однако, некоторые изменения требуют остановки виртуальной машины. В этом случае мы получим ошибку при попытке применить новые настройки с текстом:
Error: Changing the `secondary_disk`, `resources`, `platform_id`, `network_acceleration_type` or `network_interfaces` on an instance requires stopping it. To acknowledge this action, please set allow_stopping_for_update = true in your config file.
Мы должны явно разрешить для конкретных ресурсов выполнение остановки их работы для внесения изменений. В нашем файле для конкретного ресурса добавим:
|
1 2 3 4 5 6 |
... resource "yandex_compute_instance" "vm-test1" { name = "test1" allow_stopping_for_update = true ... |
* для нашей машины test1 мы указали опцию allow_stopping_for_update, которая говорит о том, что работу ресурса можно останавливать для внесения изменений.
Строим план:
terraform plan
Мы должны увидеть, что будет изменено в нашей инфраструктуре. В моем случае:
|
1 2 3 4 5 |
~ resources { ~ cores = 2 -> 4 ~ memory = 2 -> 4 # (2 unchanged attributes hidden) } |
Применяем настройки:
terraform apply
Проверяем через контроль-панель, что изменения вступили в силу.
Удаление ресурсов
Для удаления ресурса можно использовать разные приемы.
1. Например, можно указать count = 0:
|
1 2 3 |
resource "yandex_compute_instance" "vm-test1" { count = 0 ... |
2. Можно закомментировать или удалить строки ресурса из файла tf.
3. Если мы хотим оставить содержимое файлов нетронутым, но при этом удалить все ресурсы, вводим:
terraform destroy
Утилита пройдет по всем файлам tf в директории, найдет ресурсы и выполнит их удаление.
Файл state
Очень важно уметь работать с файлом состояния terraform, а также понять, что это. Данный файл появляется после первого применения сценария в том же рабочем каталоге:
ls
terraform.tfstate
В нем содержатся все изменения, которые происходили с применением terraform. Без него последний не будет знать, что уже было сделано — на практике это приведет к дублированию инфраструктуры, то есть, если мы создали сервер, потеряли файл состояния и снова запустили terraform, он создаст еще один сервер. Для больших инфраструктур с большой историей все намного критичнее.
И так, файл состояния важен с точки зрения понимания инфраструктуры самим terraform. Также у него есть еще одна функция — блокировка параллельных выполнений. Это важно для работы в командах, где одновременные действия могут привести к неожиданным последствиям. Чтобы этого не произошло, terraform создает блокировку, которая запрещает выполнения, если уже идет процесс применения плана.
Из вышесказанного делаем выводы:
- Файлы состояния нужно бэкапить.
- Они должны находиться в надежном месте.
- У всех инженеров, которые работают с инфраструктурой должен быть доступ к файлу состояния. Они не должны его копировать на свои компьютеры и использовать индивидуально.
Рассмотрим возможность хранения данного файла состояния на облачном хранилище Яндекс.
Сначала мы должны создать хранилище. Это можно сделать через веб-интерфейс, но мы это сделаем в terraform.
Но сначала мы сделаем файл:
vi variables.tf
|
1 2 3 4 |
variable "yandex_folder_id" { type = string default = "<идентификатор каталога>" } |
* где yandex_folder_id — название для нашей переменной; <идентификатор каталога> — тот идентификатор, который мы указали в файле main под аргументом folder_id.
Теперь откроем файл main:
vi main.tf
И отредактируем значение folder_id на:
|
1 2 3 |
... folder_id = var.yandex_folder_id ... |
* в данном примере мы теперь задаем folder_id не явно, а через созданную переменную.
Теперь создадим файл:
vi yandex_storage_bucket.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
resource "yandex_iam_service_account" "sa" { folder_id = var.yandex_folder_id name = "sa-test" } resource "yandex_resourcemanager_folder_iam_member" "sa-editor" { folder_id = var.yandex_folder_id role = "storage.editor" member = "serviceAccount:${yandex_iam_service_account.sa.id}" } resource "yandex_iam_service_account_static_access_key" "sa-static-key" { service_account_id = yandex_iam_service_account.sa.id description = "Static access key for object storage" } resource "yandex_storage_bucket" "state" { bucket = "tf-state-bucket-test" access_key = yandex_iam_service_account_static_access_key.sa-static-key.access_key secret_key = yandex_iam_service_account_static_access_key.sa-static-key.secret_key } |
* рассмотрим файл немного подробнее:
- yandex_iam_service_account — создание ресурса для учетной записи. В нашем примере она будет иметь название sa-testи входить в системный каталог yandex_folder_id (переменная, которую мы создали ранее).
- yandex_resourcemanager_folder_iam_member — создание роли. Она будет иметь доступ для редактирования хранилищ. В состав роли войдет созданная запись sa (с именем sa-test).
- yandex_iam_service_account_static_access_key — создаем ключ доступа для нашей сервисной учетной записи.
- yandex_storage_bucket — создаем хранилище с названием tf-state-bucket-test.
Создаем еще один файл:
vi outputs.tf
|
1 2 3 4 5 6 7 8 |
output "access_key" { value = yandex_iam_service_account_static_access_key.sa-static-key.access_key sensitive = true } output "secret_key" { value = yandex_iam_service_account_static_access_key.sa-static-key.secret_key sensitive = true } |
* это делается для получения значений аргументов access_key и secret_key и сохранения данных значений в файле состояния. Если access_key можно посмотреть в панели Яндекса, то secret_key мы увидеть не можем.
Строим план и применяем настройки:
terraform plan
terraform apply
Заходим в контроль-панель Яндекса и видим, что у нас создалось хранилище. Его мы будем использовать для хранения файлов состояний terraform.
Открываем наш файл main:
vi main.tf
Добавляем:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
terraform { ... backend "s3" { endpoint = "storage.yandexcloud.net" bucket = "tf-state-bucket-test" region = "ru-central1-a" key = "terraform/infrastructure1/terraform.tfstate" access_key = "<access_key>" secret_key = "<secret_key >" skip_region_validation = true skip_credentials_validation = true } } |
* в раздел terraform мы добавили инструкцию для хранения файла state. В нашем примере он будет размещен на бакете tf-state-bucket-test по пути terraform/infrastructure1/terraform.tfstate.
** особое внимание обратите на access_key и secret_key. В разделе terraform мы не можем указать переменные, как это делали при создании хранилища. Сами значения можно найти в нашем локальном файле state.
Используем команду:,
terraform init
Система снова инициализирует состояние текущего каталога и создаст файл state на удаленном хранилище. Чтобы убедиться, можно зайти в контроль панель, найти наше хранилище, а в нем — файл terraform/infrastructure1/terraform.tfstate.
Реальный пример
Мы развернем 2 веб-сервера и поместим их за Network load balancer.
Для этого мы создадим новый рабочий каталог:
mkdir -p /opt/terraform/yandex-network-load balancer
И перейдем в него:
cd /opt/terraform/yandex-network-load balancer
Подразумевается, что все инфраструктура создается с нуля, поэтому нужно либо удалить предыдущие наработки, либо создать новый сервисный аккаунт для storage.
Мы создадим 5 файлов:
- main.tf — в нем мы опишем инструкции для init, а именно требования к версии клиента terraform, провайдера.
- web-servers.tf — сценарий для создания 2-х веб-серверов.
- network-load-balancer.tf — создание Network Load Balancer.
- variables.tf — описание переменных.
- outputs.tf — вывод значений после отработки terraform на экран и в файл состояния.
1. Создаем файл main.tf:
vi main.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
terraform { required_version = "= 1.1.7" required_providers { yandex = { source = "yandex-cloud/yandex" version = "= 0.73" } } } provider "yandex" { token = "<OAuth>" cloud_id = "<идентификатор облака>" folder_id = "<идентификатор каталога>" zone = "<зона доступности по умолчанию>" } |
* это стандартный вариант файла main.tf, который мы разбирали в начале.
2. web-servers.tf:
vi web-servers.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
data "yandex_compute_image" "lamp" { family = "lamp" } data "yandex_compute_image" "lemp" { family = "lemp" } resource "yandex_compute_instance" "vm-test1" { name = "vm-test1" allow_stopping_for_update = true resources { cores = 2 memory = 2 } boot_disk { initialize_params { image_id = data.yandex_compute_image.lamp.id } } network_interface { subnet_id = yandex_vpc_subnet.subnet_terraform.id nat = true } } resource "yandex_compute_instance" "vm-test2" { name = "vm-test2" allow_stopping_for_update = true resources { cores = 2 memory = 2 } boot_disk { initialize_params { image_id = data.yandex_compute_image.lemp.id } } network_interface { subnet_id = yandex_vpc_subnet.subnet_terraform.id nat = true } } resource "yandex_vpc_network" "network_terraform" { name = "network_terraform" } resource "yandex_vpc_subnet" "subnet_terraform" { name = "subnet_terraform" zone = "ru-central1-a" network_id = yandex_vpc_network.network_terraform.id v4_cidr_blocks = ["192.168.15.0/24"] } |
* в данном примере мы создадим 2 виртуальные машины — одну с образом lamp (Apache), вторую на lemp (NGINX).
3. network-load-balancer.tf:
vi network-load-balancer.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
resource "yandex_lb_network_load_balancer" "lb-test" { name = "lb-test" listener { name = "listener-web-servers" port = 80 external_address_spec { ip_version = "ipv4" } } attached_target_group { target_group_id = yandex_lb_target_group.web-servers.id healthcheck { name = "http" http_options { port = 80 path = "/" } } } } resource "yandex_lb_target_group" "web-servers" { name = "web-servers-target-group" target { subnet_id = yandex_vpc_subnet.subnet_terraform.id address = yandex_compute_instance.vm-test1.network_interface.0.ip_address } target { subnet_id = yandex_vpc_subnet.subnet_terraform.id address = yandex_compute_instance.vm-test2.network_interface.0.ip_address } } |
* в данном сценарии мы:
- создаем target_group из 2-х наших веб-серверов.
- создаем балансировщик lb-test.
- привязываем к балансировщику target_group.
4. variables.tf:
vi variables.tf
|
1 2 3 4 |
variable "yandex_folder_id" { type = string default = "<folder_id>" } |
* создадим переменную с folder_id, в котором мы должны работать. Выше мы уже делали такую переменную.
5. outputs.tf:
vi outputs.tf
|
1 2 3 |
output "lb_ip_address" { value = yandex_lb_network_load_balancer.lb-test.* } |
* на самом деле, это не обязательно — информацию о созданном балансировщике можно посмотреть в контроль панели, но для примера мы решили это рассмотреть.
Готово. После применения данного сценария мы получим то, что хотели — две виртуальные машины + балансировщик сети, который будет распределять запросы между данными серверами.