Thank you for reading this post, don't forget to subscribe!
Apache Kafka — брокер сообщений, реализующий паттерн Producer-Consumer с хорошими способностями к горизонтальному масштабированию или по-русски распределенная система передачи сообщений, рассчитанная на высокую пропускную способность. Это Open Source разработка, созданная компанией LinkedIn на JVM стеке (Scala).
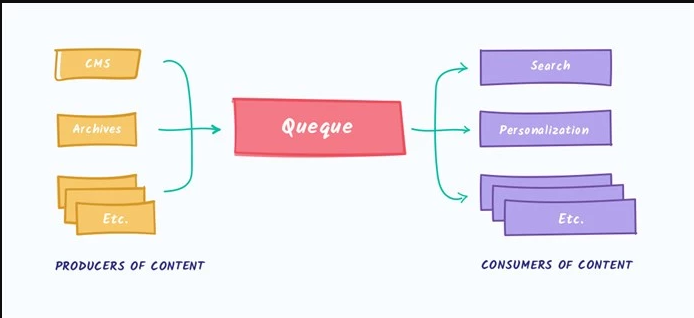
Горизонтально масштабируя какую-либо систему, вы поневоле делаете её распределённой, а работа с распределённой системой имеет свои особенности.
Формально, для описания свойств распределённых систем существует CAP-теорема.
Главные достоинства Apache Kafka:
- Скорость: один узел кластера может обрабатывать сотни мегабайт записей в секунду.
- Масштабируемость: кластер можно прозрачно расширять без простоя, потоки данных партицированы.
- Надежность: сообщения в кластере реплицированы, каждый узел может содержать терабайты данных без потерь в производительности.
В распределённой системе невозможно обеспечить одновременное выполнение всех трёх свойств: консистентности, доступности, устойчивости к сбоям узлов.
Что это за свойства:
- Консистентность (Consistency)
- Говорит о том, что система всегда выдаёт только логически непротиворечивые ответы. Не бывает такого, что вы добавили в корзину товар, а после рефреша страницы его там не видите.
- Доступность (Availability)
- Означает, что сервис отвечает на запросы, а не выдаёт ошибки о том, что он недоступен.
- Устойчивость к сбоям сети (Partition tolerance)
- Означает, что распределённая по кластеру система работает в расчёте на случаи произвольной потери пакетов внутри сети.
- С точки зрения CAP-теоремы, Kafka имеет CA*, т.е. выполняются условия консистентности и доступности, но не гарантируется устойчивость к сбоям в сети — по отзывам пользователей, Kafka не очень устойчива к netsplit (моменту, когда ваш кластер, например, разваливается пополам), хотя официальной документации на этот счёт мы не нашли.
На самом низком уровне Kafka — это просто распределённый лог-файл. То есть, по сути, файл, разбитый на несколько частей (партиций) и «раскатанный» на несколько узлов кластера. Запись в этот файл всегда происходит в конец. Разделение файла на части необходимо для ускорения чтения из очереди и горизонтального масштабирования. Ваш Topic (тема) может быть «порезан» на сколько угодно частей. Соответственно, вы можете разделить Topic на сколько угодно серверов. Из каждой партиции может читать не более одного Consumer (читатель). Это значит, что максимальное число параллельных читателей равно количеству частей, на которые разбит ваш Topic.
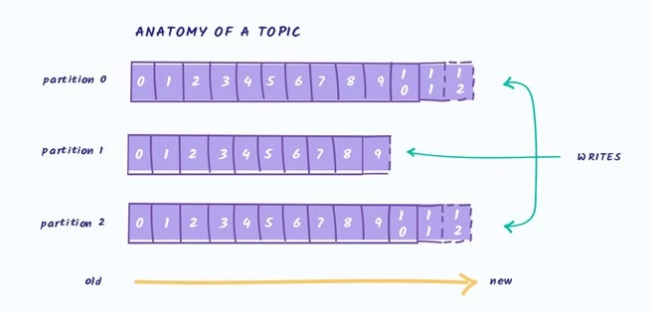
Соответственно, для одной партиции топика гарантируется очерёдность сообщений, так как из каждой партиции может читать не более одного читателя.
У каждого сообщения есть свой сквозной номер внутри патриции. В терминах Kafka это называется offset. При чтении из партиции читатель делает коммит оффсета. Это необходимо для того, чтобы, если, например, текущий читатель упадёт, то следующий (новый читатель) начнёт с последнего коммита.
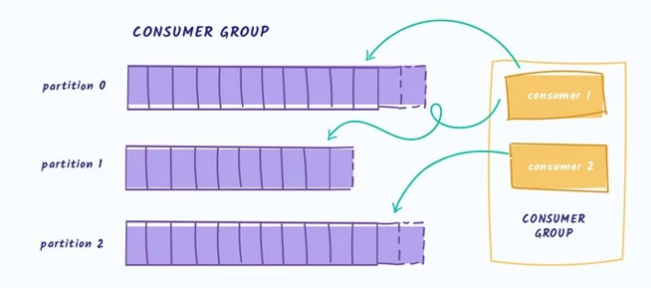
Читатели объединяются в группы, что так и называется — consumer group. При добавлении нового читателя или падении текущего, группа перебалансирутся. Это занимает какое-то время, поэтому лучший способ чтения — подключить читателя и не переподключать его без необходимости.
Что касается доступности, Kafka обеспечивает репликацию сообщений и disk persistence, сохраняя сообщения на диск.
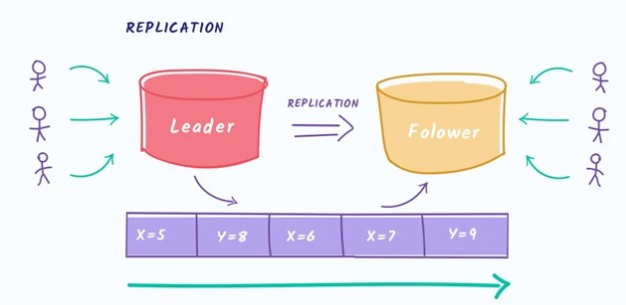
Формат репликации называется InSync. Это значит, что слейвы (в терминах Kafka это фолловеры) сами постоянно спрашивают мастера о новых сообщениях. Это pull-модель. Синхронностью/асинхронностью репликации вы можете управлять сами, указывая какие гарантии (acknowledgement) вы хотите получить при записи в очередь. Kafka поддерживает три режима:
- отправить и не дожидаться подтверждения записи;
- отправить и дождаться подтверждения на мастер-ноде;
- отправить и дождаться подтверждения на всех репликах.
Вы должны найти компромисс между возможностью потери сообщений и минимальным откликом приложения. Чем выше гарантии доставки, тем, соответственно, дольше запись в очередь.
Поскольку Kafka гарантирует консистентность, для читателей сообщение будет видно только после записи по всем репликам. Репликация происходит отдельно для каждой партиции в топике.
Если вспомнить про disk persistence, то он вытекает из устройства Kafka. Так как вся система — это просто лог, то все сообщения в любом случае попадают на диск и это невозможно выключить, но в конфигурации можно подкрутить ручку, какими периодами сообщения падают на диск. Что, соответственно, уменьшит ваши гарантии на потерю сообщений, но увеличит производительность.
Клиенты для Kafka достаточно интеллектуальные и работают на уровне TCP. В коробке с Kafka лежит клиент на Java (так как сама Kafka написана на Scala) и библиотека на C.
Для тех, кто пишет на .NET или, например, Python, существуют open source биндинги к этой библиотеке на С. Так как это open source разработки, исходный код у вас на руках. Другое дело, что и патчить иногда придётся вам.
Выводы: Apache Kafka менее удобна, чем тот же RabbitMQ, но если вы не можете терять сообщения, то вариант с Kafka подходит больше. К тому же у Kafka гораздо больше scalability (расширяемость).
Для хранения метаданных в Kafka используется сервис под названием Zookeeper.
Zookeeper
– это распределенное хранилище ключей и значений. Оно сильно оптимизировано для считывания, но записи в нем происходят медленнее. Чаще всего Zookeeper применяется для хранения метаданных и обработки механизмов кластеризации (пульс, распределенные операции обновления/конфигурации, т.д.).
Таким образом, клиенты этого сервиса (брокеры Kafka) могут на него подписываться – и будут получать информацию о любых изменениях, которые могут произойти. Именно так брокеры узнают, когда ведущий в секции меняется. Zookeeper исключительно отказоустойчив (как и должно быть), поскольку Kafka сильно от него зависит.
Он используется для хранения всевозможных метаданных, в частности:
- Смещение групп потребителей в рамках секции (хотя, современные клиенты хранят смещения в отдельной теме Kafka)
- ACL (списки контроля доступа) — используются для ограничения доступа /авторизации
- Квоты генераторов и потребителей — максимальные предельные количества сообщений в секунду
- Ведущие секций и уровень их работоспособности
Когда стоит использовать Kafka?
Kafka позволяет пропускать через централизованную среду огромное количество сообщений, а затем хранить их, не беспокоясь о производительности и не опасаясь, что данные будут потеряны.
Таким образом, Kafka отлично устроится в самом центре вашей системы и будет работать как связующее звено, обеспечивающее взаимодействие всех ваших приложений. Kafka может быть центральным элементом событийно-ориентированной архитектуры, что позволит вам как следует отцепить приложения друг от друга.
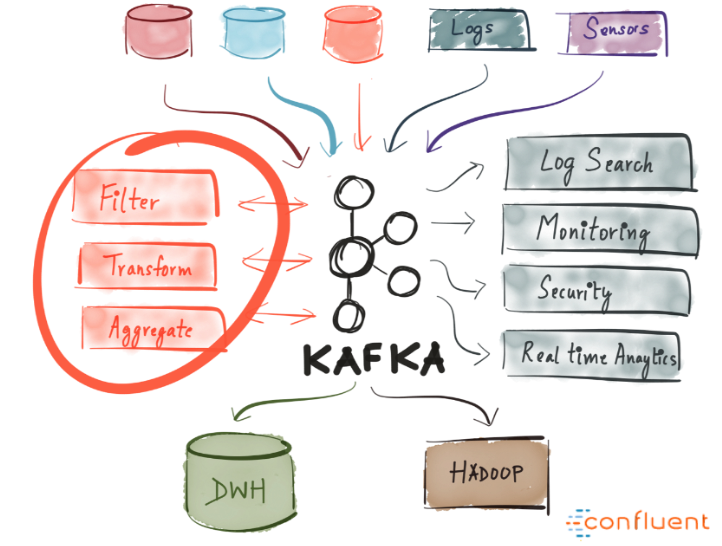
Kafka позволяет с легкостью разграничить коммуникацию между различными (микро)сервисами.